
Redis主从集群切换数据丢失的解决方案
一、数据丢失的情况
异步复制同步丢失
集群产生脑裂数据丢失
1.异步复制丢失
对于Redis主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给master节点的时候,客户端会返回OK,然后同步到各个slave节点中。
如果此时master还没来得及同步给slave节点时发生宕机,那么master内存中的数据会丢失;
要是master中开启持久化设置数据可不可以保证不丢失呢?答案是否定的。在master 发生宕机后,sentinel集群检测到master发生故障,重新选举新的master,如果旧的master在故障恢复后重启,那么此时它需要同步新master的数据,此时新的master的数据是空的(假设这段时间中没有数据写入)。那么旧master中的数据就会被刷新掉,此时数据还是会丢失。
2.集群产生脑裂
首先我们需要理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁来控制呢?在分布式集群中,分布式协作框架zookeeper很好的解决了这个问题,通过控制半数以上的机器来解决。
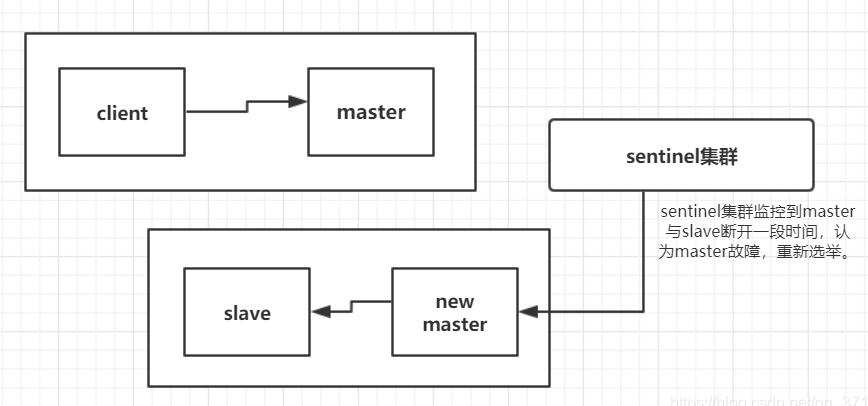
那么在Redis中,集群脑裂产生数据丢失的现象是怎么样的呢?
假设我们有一个redis集群,正常情况下client会向master发送请求,然后同步到salve,sentinel集群监控着集群,在集群发生故障时进行自动故障转移。

此时,由于某种原因,比如网络原因,集群出现了分区,master与slave节点之间断开了联系,sentinel监控到一段时间没有联系认为master故障,然后重新选举,将slave切换为新的master。但是master可能并没有发生故障,只是网络产生分区,此时client任然在旧的master上写数据,而新的master中没有数据,如果不及时发现问题进行处理可能旧的master中堆积大量数据。在发现问题之后,旧的master降为slave同步新的master数据,那么之前的数据被刷新掉,大量数据丢失。
在了解了上面的两种数据丢失场景后,我们如何保证数据可以不丢失呢?在分布式系统中,衡量一个系统的可用性,我们一般情况下会说4个9,5个9的系统达到了高可用(99.99%,99.999%,据说淘宝是5个9)。对于redis集群,我们不可能保证数据完全不丢失,只能做到使得尽量少的数据丢失。
二、如何保证尽量少的数据丢失?
在redis的配置文件中有两个参数我们可以设置:
min-slaves-to-write 1 min-slaves-max-lag 10
min-slaves-to-write默认情况下是0,min-slaves-max-lag默认情况下是10。
以上面配置为例,这两个参数表示至少有1个salve的与master的同步复制延迟不能超过10s,一旦所有的slave复制和同步的延迟达到了10s,那么此时master就不会接受任何请求。
我们可以减小min-slaves-max-lag参数的值,这样就可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往master中写入数据。
那么对于client,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入master来保证数据不丢失;也可以将数据写入kafka消息队列,隔一段时间去消费kafka中的数据。
通过上面两个参数的设置我们尽可能的减少数据的丢失,具体的值还需要在特定的环境下进行测试设置。
补充:Redis Cluster 会丢数据吗?
Redis Cluster 不保证强一致性,在一些特殊场景,客户端即使收到了写入确认,还是可能丢数据的。
场景1:异步复制
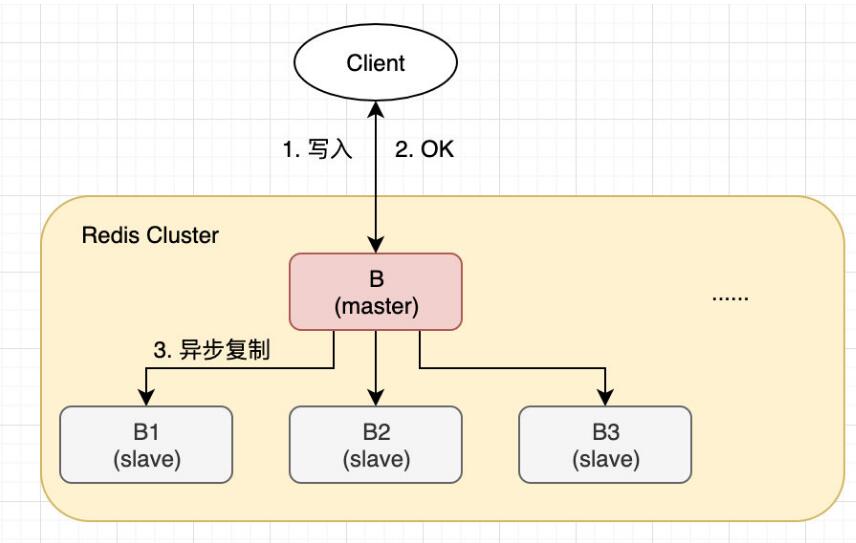
client 写入 master B
master B 回复 OK
master B 同步至 slave B1 B2 B3
B 没有等待 B1 B2 B3 的确认就回复了 client,如果在 slave 同步完成之前,master 宕机了,其中一个 slave 会被选为 master,这时之前 client 写入的数据就丢了。
wait 命令可以增强这种场景的数据安全性。
wait 会阻塞当前 client 直到之前的写操作被指定数量的 slave 同步成功。
wait 可以提高数据的安全性,但并不保证强一致性。
因为即使使用了这种同步复制方式,也存在特殊情况:一个没有完成同步的 slave 被选举为了 master。
场景2:网络分区
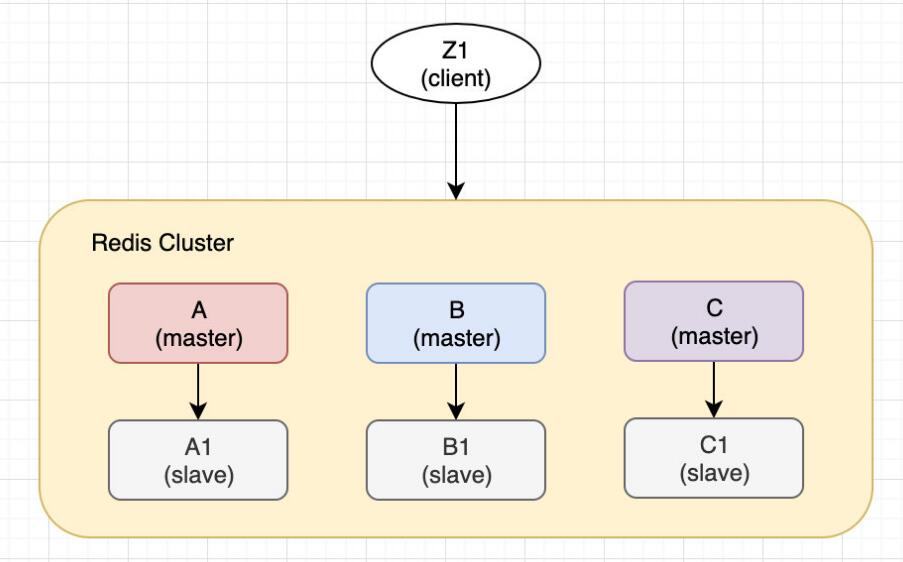
6个节点 A, B, C, A1, B1, C1,3个master,3个slave,还有一个client,Z1。
发生网络分区之后,形成了2个区,A, C, A1, B1, C1 和 B Z1。
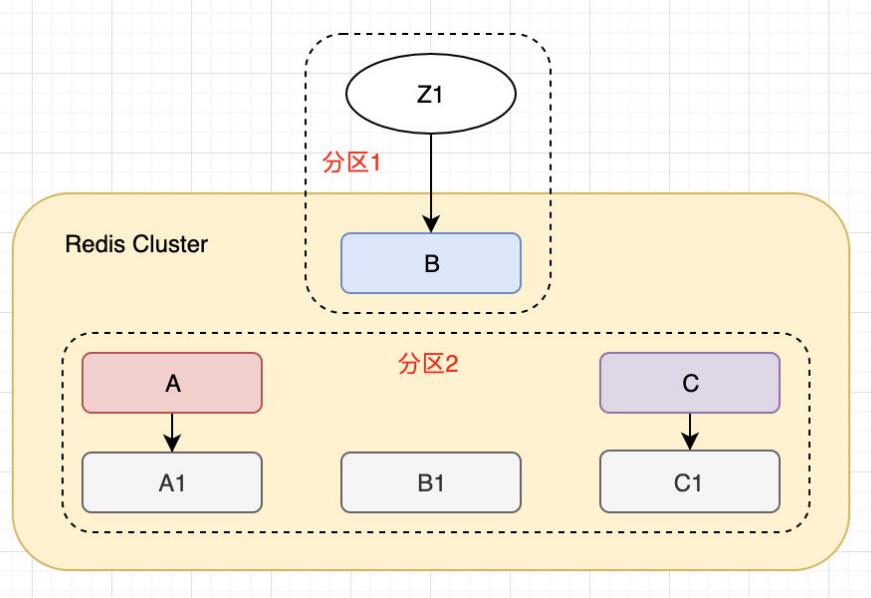
这时 Z1 还是可以向 B 写入的,如果短时间内分区就恢复了,那就没问题,整个集群继续正常工作,但如果时间一长,B1 就会成为所在分区的 master,Z1 写入 B 的数据就丢了。
maximum window(最大时间窗口) 可以减少数据损失,可以控制 Z1 向 B 写入的总数:
过去一定时间后,分区的多数边就会进行选举,slave 成为 master,这时分区少数边的 master 就会拒绝接收写请求。
这个时间量是非常重要的,称为节点过期时间。
一个 master 在达到过期时间后,就被认为是故障的,进入 error 状态,停止接收写请求,可以被 slave 取代。
小结
Redis Cluster 不保证强一致性,存在丢失数据的场景:
异步复制
在 master 写成功,但 slave 同步完成之前,master 宕机了,slave 变为 master,数据丢失。
wait 命令可以给为同步复制,但也无法完全保证数据不丢,而且影响性能。
网络分区
分区后一个 master 继续接收写请求,分区恢复后这个 master 可能会变为 slave,那么之前写入的数据就丢了。
可以设置节点过期时间,减少 master 在分区期间接收的写入数量,降低数据丢失的损失。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
