数据库快照抽取:备份数据更高效 (数据库snapshot抽取)
随着企业对数据存储的需求不断增长,数据库技术得到了广泛应用。数据库有着很多优点,例如数据安全性高、数据共享性能好等,但也存在着一些弊端,例如数据恢复时间长、备份数据的容量大等。
为了解决备份数据的容量大、备份和恢复时间耗时的问题,数据库快照抽取成为了备份和恢复数据的重要技术之一。本篇文章将介绍数据库快照以及快照抽取的原理、优势和应用范围。
一、数据库快照
数据库快照是指一种特殊的备份机制,它可以将整个数据库的图像(snapshot)复制到相应的存储位置,而不会影响到生产数据库的正常运行。
在生成数据库快照时,数据库系统会暂停I/O处理,锁定所有数据页,并将它们写入快照中。快照中的数据页不会随着数据库的更新而发生变化,因此在备份和恢复数据时可以大大提高备份/还原效率。
数据库快照提供了如下几点优势:
1. 快速恢复:当在生产数据库中遇到了错误时,可以在不影响生产环境的前提下,使用数据库快照快速恢复到数据库出错之前的状态。
2. 方便备份:使用数据库快照可以快速备份整个数据库而不会中断业务运行,这样就可以节省备份时间,缩短恢复时间,提高数据安全性。
3. 数据隔离:在测试环境中可以使用数据库快照来隔离测试数据,这样在测试过程中对生产数据的影响可以最小化。
4. 提高数据可用性:在应对软硬件故障或者网络问题时,快照可以充当一个备份的功能。
二、数据库快照抽取
数据库快照抽取通过使用存储别名(storage alias)来创建快照。其原理是将快照转换成短暂的、“干净”的数据库副本,可以使用数据库管理工具在其中执行查询和DML语句。使用了快照抽取后,用户可以只恢复某一时间点的数据或某一表的数据,而不是一整个快照。
数据库快照抽取有如下优势:
1. 备份效率高:快照抽取可以将普通的全量备份转换成基于增量的备份,大大减少备份时间和存储空间。
2. 恢复数据效率高:当需要恢复数据时,只需要恢复特定的表、特定的数据与特定的时间段,而不需要将整个数据库恢复到最初状态。
3. 降低备份数据的存储空间:快照抽取可以选择只备份最新数据的特点,可以大大降低备份数据的存储空间及对存储空间的使用。
三、数据库快照抽取的应用范围
数据库快照抽取可以广泛应用于以下领域:
1. 教育和科研领域:在建立教育或科研项目时,数据库快照抽取可以用于快速创建项目的测试环境,以提高开发人员的效率。
2. 金融行业:需要数据库快照备份来保证金融数据的安全性。而数据库快照抽取可以大大缩短备份时间。
3. 互联网行业:在互联网行业中,数据库快照抽取可以用于在线交易平台等系统中,通过备份特定的数据将交易损失降至最小。
4. 大型企业:一些大型企业需要大量的数据备份和存储,数据库快照抽取技术可以快速有效地进行备份,减少了备份和还原的时间。
数据库快照抽取技术是一种非常重要的数据库备份技术,可以大大简化数据备份和恢复的工作,并提高数据的可靠性、可用性和安全性。因此,对于那些需要频繁备份数据并且想要提高备份效率的企业来说,数据库快照抽取是非常有用的技术。
相关问题拓展阅读:
数据库详解之事务
究竟什么是数据库的事务,为什么数据库需要支持事务,为了实现数据库事务各种数据库的是如何设计的。还是只谈理解,欢迎大家来讨论。
1. 数据库事务是什么
事务的定义,已经有太多文章写过,我就不重复了。我理解的事务就是用来保证数据操作符合业务逻辑要求而实现的一系列功能。换句话说,如果数据库不支持事务,上面业务系统的程序员就需要自己写代码保证相关数据处理逻辑的正确性。而数据库事务就是把一系列保证数据库处理逻辑正确性的通用功能在数据库内实现,并且尽量提高效率。
举个例子,数据库最开始普及就是在金融业,银行的存取款场景就是一个最典型的OLTP数据库场景,而事务就是设计用来保证类似场景的业务逻辑正确性的。
!(
,type_ZHJvaWRzYW5zZmFGJhY2s,shadow_50,text_Q1NETiBAd2luZHRhbGtlcnd5,size_20,color_FFFFFF,t_70,g_se,x_16)
**原子性**,如果你要给家人转账,必须在你的账户里扣掉100块,在家人账户里加上100块,这两笔操作需要一起完成,业务逻辑才是正确的。但是程序在做修改的时,肯定会有先后顺序,试想一下程序扣了你的钱,这个时候程序崩溃了,家人账户的钱没有加上。那这100块是不是消失了?你是不是要发疯?那么,就把这两笔操作放进一个事务里,通过原子性保证,这两笔操作要么都成功,要么都失败。这样才能保证业务逻辑的正确性。
**一致性**,有很多文章讲过一致性,但是很多人会把一致性跟原子性混在一起说。事务的一致性指的是指每一个事务必须保证执行之后所有库内的规则依旧成立。比如内外键,constraint,触发器等。举例来说,你在储蓄卡里有100元,理财账户里有100元,基金账户有100元,那么你在资产总和里会看到300元,这个300元必须是其他三个账户余额加在一起得到的。你在给家人转帐100元是从储蓄卡里转出去了100元,那么在数据库上可以通过创建触发器的方式,当储蓄卡余额账户减100元的同时,把资产总和也同步减去100,不然的话,就会出现逻辑上的错误,因为你已经转走了100块储蓄卡余额,实际资产总和应该是200,如果还是300,数据库状态就不一致了。所以实现事务的时候,必须要保证相关联的触发器以及其他所有的内部规则都执行成功,事务才能算执行成功。如果在减去资产总时出错,那么这笔转帐交易也不能成功。因为这样数据库就会进入不一致的状态。
那么这里跟原子性的区别到底在哪里呢?原子性是指个多个用户指令之间必须作为一个整体完成或失败,而一致性更多是数据库内的相关数据规则必须同时完成或失败。
**持久性**,最容易理解的一个,事务只要提交了,那么对数据库的修改就会保存下来不会丢了。简单来说,只要提交了,数据库就算崩溃了,重启之后你刚存的100块依然在你的账户里。
**隔离性**,每个事务相对于其他的事务是有一定独立性的,不能互相影响。因为数据库需要支持并发的操作来提高效率。在并发操作时,一定要通过操作之间的隔离来保证业务逻辑的正确性。比如,你转帐100块给家人,一系列操作的最后一步可能是输入验证码,这个时候转帐还没有完成,但是在数据库里你的账户对应的记录中已经减去100块,家人账户也加了100块,就等着验证码输入以后,事务提交,完成操作。那么,这个时候,家人通过手机银行能够查到这100块么?你的答案可能是不能,因为这样才符合业务逻辑,因为你的转帐操作还没有提交,事务还没有完成。那么数据库就应该保证这两个并发操作之间具有一定的隔离性。
那么到底应该隔离到什么程度呢?隔离性又分为4个等级:由低到高依次为Read uncommitted(读未提交)、Read committed(读提交)、Repeatable read(可重复读取)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻象读这几类问题。这些东西是什么意思?请有兴趣的小伙伴自行百度,很多文章都写的很清楚。
那么怎么理解不同的隔离等级呢,首先要理解并发操作,并发操作就是指有不同的用户同时对一个数据进行读、写操作,那么在这个过程中,每个用户应该看到什么数据才能保证业务逻辑的正确性呢? 如果是前面存取款的场景,我必须看到的是已经存进来的钱,也就是必须是已经提交的事务。而12306刷火车票呢,你可以看到有10张余票,但是在下单的时候告诉你票卖完了,因为同时有10个用户把票买掉了,你需要重新刷余票,这个也是可以接受的,也就是说我可以读到一些虚假的余票,这样在业务上也没有什么问题。那么在设计这两个不同系统时,就可以选择不同的事务隔离级别来实现不同的并发效果。不同的隔离等级就是要在系统的并发性和数据逻辑的严谨性之间做出的平衡。
2. 数据库如何实现事务
数据库实现事务会有多种不同的方式,但基本的原理类似,比如都需要对事务进行统一的编号处理,都需要记录事务的状态(是成功了还是失败了),都需要在数据存储的层面对事务进行支持,以明确哪些数据是被哪些事务、插入、修改和删除的。同时还会记录事务日志等,对事务进行系统化的管理以实现数据的原子性,一致性和持久性。
要实现事务的隔离性,最基础的就是通过加锁机制把并发操作适当的串行化来保证数据操作的正确逻辑。但是为了要保证系统具有良好的并发性能,必须要在实现事务隔离性时需要找到合理的平衡点。大部分数据库(包括Oracle,MySQL,Postgres在内)在做并发控制的时候都会采用MVCC(多版本并发控制)的机制来保证系统具有较高的并发性,不同数据库实现MVCC的具体方案也不尽相同,但其基本原理类似。
3. MVCC实现原理
所谓MVCC,就是数据库中的同一查询根据相关事务执行的先后顺序以及隔离级别的不同,可能会存在不同版本的结果,通过这样的手段来保证大部分查询操作不会被修改操作阻塞并保证数据逻辑的正确性。也就是数据库通过保存多个版本的数据( 历史 数据)来提高系统的并发查询能力。简单来说就是用存储空间来交换并发能力。下面以Postgres为例介绍一下MVCC的一种实现方式帮助大家理解这个重要的数据库概念。通过下面的图来解释Posrgres里最基本的数据可见性是如何实现多版本控制的。
!(
,type_ZHJvaWRzYW5zZmFGJhY2s,shadow_50,text_Q1NETiBAd2luZHRhbGtlcnd5,size_20,color_FFFFFF,t_70,g_se,x_16)
首先,Postgres里的每一个事务都有编号,这里可以简单理解为时间顺序编号,编号越大的事务发生越晚。然后,数据库里的每一行记录都会保存创建这条记录的事务号(Cre),也会在记录删除时保存删除这条记录的事务号(Exp),换句话说,只要Exp这里一列里记录了事务编号,就说明这条记录被删除了。那么一个事务应该能看见那些记录呢?Postgres里每一个事务都会保存一个当前系统的事务快照(Snapshot),这个快照里会保存事务创建时当前系统的更高(最晚)事务编号,以及目前还在进行中的事务编号。那么如上图所示的一个事务的快照里更高事务编号为100,目前正在进行的事务有25,50和75。那么对应左边数据记录,这6行数据的可见性就如同标注的一般:
之一行,Cre 30,没有删除,在100这个时间点,应该能看到。
第二行,Cre 50,没有删除,但是50这个事务还没有提交,正在进行中,所以看不见。
第三行,Cre 110,没有删除,但是100这个时间点110事务还没有发生,所以看不见。
第四行,Cre 30,Exp 80,在80的时候数据被删掉了,所以看不见。
第五行,Cre 30,Exp 75,在30的时候被创建,75时候被删掉了,但是75这个事务在100的时候还没有提交,所以这条记录在100的时候还没有删掉,所以看得见。
第六行,Cre30,Exp 110,在30的时被创建,110时候被删掉,但是在100时候,110还没有发生,所以看得见。
综上,就是这个事务对这六条记录的可见性,也就是一个数据版本。那么大家可以看一下如果另一个事务的快照里存的是更高事务编号为110,正在进行的事务为50,那么它能看到的数据应该是哪几行呢?同时大家也看到,Postgres里删除一行数据其实就是在这一行的Exp这个列记录一个删除事务的编号,相当于做了一个删除标记,而数据没有真正被删除,因此Postgres数据库需要定期做数据清理操作(Vacuum)。Pstgres的在现实场景里会比这里介绍的要复杂,因为我们这里假定所有的事务最终都是正确提交了,如果存在某些事务没有提交的情况,那么可见性就会更加复杂,这里不再展开了。
如何创建数据库快照
任何能创建数据库的用户都可以创建数据库快照。创建快照的唯一方式是使用 Transact-SQL。注意:有关命名数据库快照、设置创建数据库快照的时间和限制数据库快照成员的注意事项,请参阅创建数据库快照。创建数据库快照根据源数据库的当前大小,确保有足够的磁盘空间存放数据库快照。数据库快照的更大大小为创建快照时源数据库的大小。使用 AS SNAPSHOT OF 子句对文件执行 CREATE DATABASE 语句。创建快照需要指定源数据库的每个数据库文件的逻辑名称。有关创建数据库快照的语法的正式说明,请参阅 CREATE DATABASE (Transact-SQL)。注意:创建数据库快照时,CREATE DATABASE 语句中不允许有日志文件、脱机文件、还原文件和不起作用的文件。示例本节包含创建数据库快照的示例。A. 对 AdventureWorks 数据库创建快照此示例对AdventureWorks数据库创建数据库快照。快照名称AdventureWorks_dbss_1800及其稀疏文件的名称AdventureWorks_data_1800.ss指明了创建时间 6 P.M.(1800 小时)。复制代码CREATE DATABASE AdventureWorks_dbss1800 ON( NAME = AdventureWorks_Data, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\Data\AdventureWorks_data_1800.ss’ )AS SNAPSHOT OF AdventureWorks;GO注意:示例中随意使用了扩展名 .ss。B. 对 Sales 数据库创建快照此示例对Sales数据库创建数据库快照sales_snapshot1200。
什么是snapshot database
中文是快照数据库
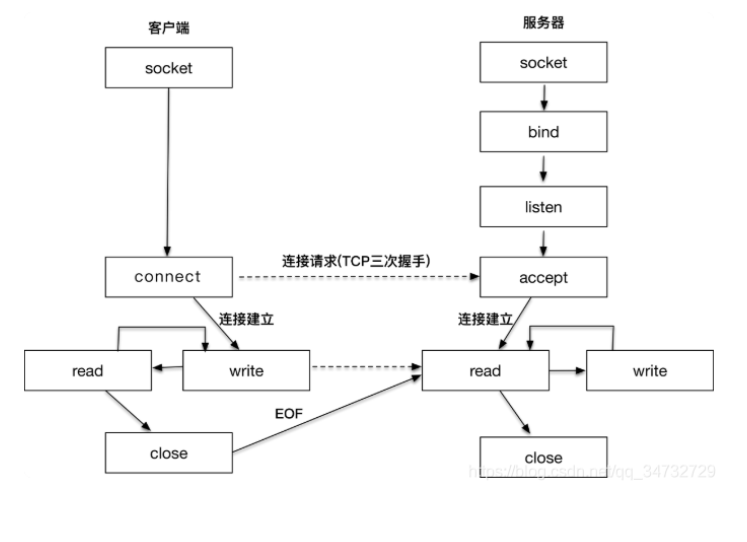
我们可以知道5000这个地址是在第9页的第392个字节处,于是我们的NF_read函数将这样发送命令和参数
column_addr=5000%512;
page_address=(5000>>9);
NF_CMD=0x01;//要从2nd half开始读取 所以要发送命令0x01
NF_ADDR= column_addr &0xff;//1st Cycle A
NF_ADDR=page_address& 0xff
NF_ADDR=(page_address>>8)&0xff; //3rd.Cycle A
NF_ADDR=(page_address>>16)&0xff;//4th.Cycle A
向NandFlash的命令寄存器和地址寄存器发送完以上命令和参数之后,我们就可以从rNFDATA寄存器(NandFlash数据寄存器)读取数据了.
快照数据库
关于数据库snapshot抽取的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。