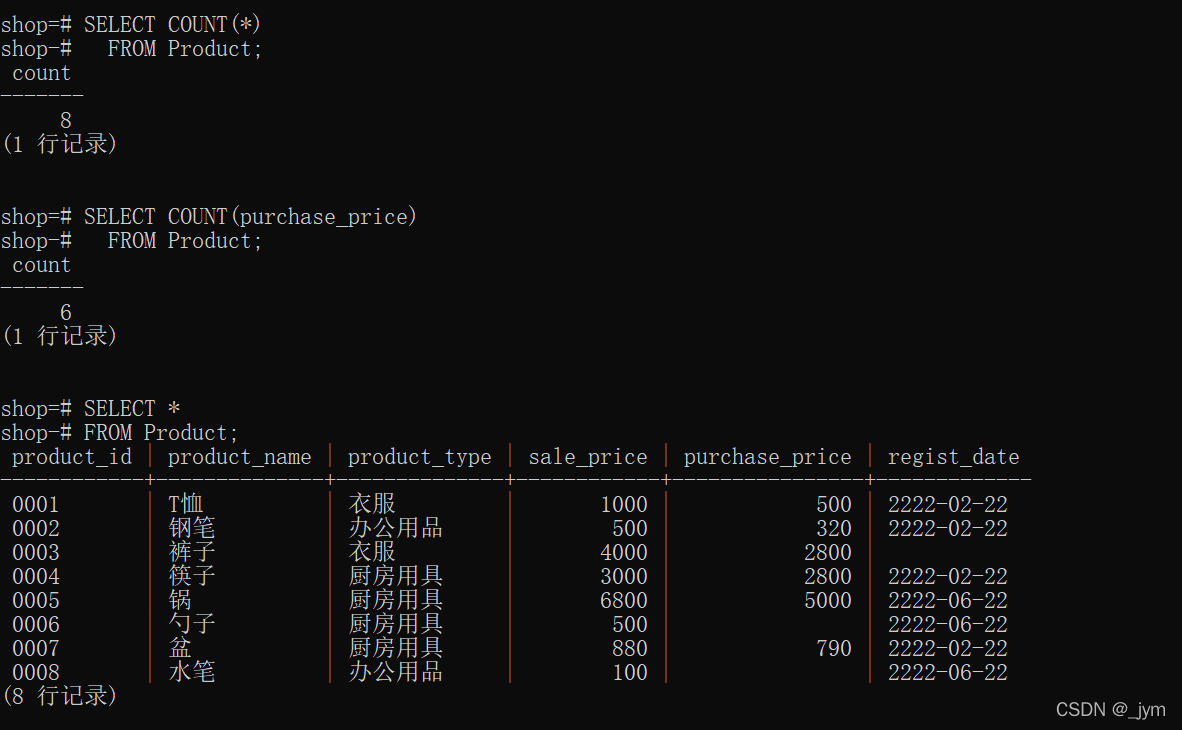
Linux如何快速查询HTTP请求的响应时间 (linux怎么查询请求耗时)
在当今的信息时代,网络已经成为人们工作、学习和生活的重要组成部分。而HTTP请求的响应时间,是衡量网站性能的重要指标之一。因此,快速查询HTTP请求的响应时间,对于网站的管理和维护非常必要。本文将介绍如何通过Linux系统快速查询HTTP请求的响应时间。
一、使用cURL命令查询HTTP响应时间
cURL是一款开源的命令行工具,可用于向服务器发起网络请求。我们可以使用cURL命令来测试HTTP响应时间。具体操作如下:
1. 打开终端,输入以下命令安装cURL工具:
sudo apt-get install curl
2. 使用以下命令向目标网站发起http请求,并显示响应时间:
curl -o /dev/null -s -w “%{time_total}\n” http://www.bdu.com
其中,“-o /dev/null”参数表示将请求结果输出到/dev/null,不显示在终端上;“-s”参数表示关闭进度条;“-w”参数表示输出响应时间。
通过这个方法,我们可以快速地得到目标网站请求的响应时间。
二、使用httpstat命令查询HTTP响应时间
httpstat是基于cURL的一款命令行工具,主要用于展示HTTP请求的过程。它可以详细地展示请求的各个阶段所消耗的时间,从而让我们更加深入地了解请求的性能。具体操作如下:
1. 打开终端,输入以下命令安装httpstat:
pip install httpstat
2. 使用以下命令向目标网站发起http请求,并显示请求过程中各个阶段的响应时间:
httpstat http://www.bdu.com
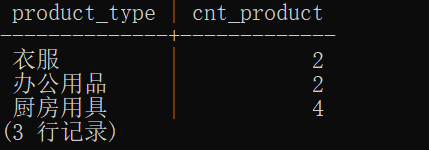
运行完这个命令后,我们将会得到如下结果:
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0xa6e4ca7e00002317
Cache-Control: private
Content-Type: text/html; charset=utf-8
Date: Thu, 23 Sep 2023 10:23:33 GMT
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Server: BWS/1.1
Set-Cookie: BDORZ=27315; max-age=86400; domn=.bdu.com; path=/
Tracecode: 0
X-Content-Type-Options: nosniff
X-Powered-By: HPHP
X-Xss-Protection: 1; mode=block
Transfer-Encoding: chunked
DNS Lookup : 22.74 ms
TCP Connection : 34.08 ms
TLS Connection : 0.00 ms
Server Processing : 4.17 ms
Content Transfer : 106.32 ms
Total : 167.32 ms
从上面的结果可以看到,每个阶段的请求时间都被详细地列出来了,我们可以更加方便地了解到每个阶段的性能情况。
三、使用ab命令查询HTTP响应时间
ab是Apache Bench的缩写,是Apache自带的一款基准测试工具,主要用于测试Web服务器的性能。然而,ab也可以用来测试HTTP请求的响应时间。具体操作如下:
1. 打开终端,输入以下命令安装ab工具:
sudo apt-get install apache2-utils
2. 使用以下命令向目标网站发起http请求数量为1000的测试,并显示每个请求的响应时间:
ab -n 1000 -c 100 http://www.bdu.com
其中,“-n”参数表示发起1000个请求,“-c”参数表示并发数为100。
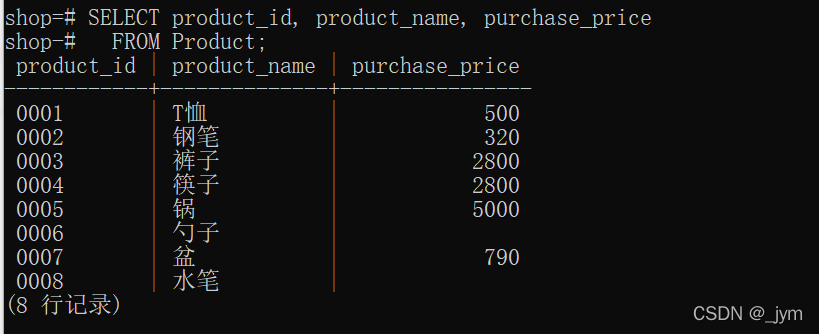
运行完这个命令后,我们将会得到如下结果:
Server Software: BWS/1.1
Server Hostname: www.bdu.com
Server Port: 80
Document Path: /
Document Length: 23809 bytes
Concurrency Level: 100
Time taken for tests: 48.521 seconds
Complete requests: 1000
Fled requests: 0
Total transferred: 24104000 bytes
HTML transferred: 23809000 bytes
Requests per second: 20.62 [#/sec] (mean)
Time per request: 4852.095 [ms] (mean)
Time per request: 48.521 [ms] (mean, across all concurrent requests)
Transfer rate: 483.41 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 1 30 16.2 29 85
Processing: 129 4652 4122.8 3045 22870
Wting: 63 3648 2849.9 1959 19841
Total: 140 4682 4131.1 3069 22888
Percentage of the requests served within a certn time (ms)
50% 3069
66% 7253
75% 9912
80% 10852
90% 18545
95% 21437
98% 22240
99% 22399
100% 22888 (longest request)
从上面的结果可以看到,ab工具不仅可以显示请求的响应时间,还可以显示每个请求的性能指标。
本文介绍了三种查询HTTP请求的响应时间的方法。其中,cURL和httpstat都使用了cURL库来发起网络请求,而ab则是Apache自带的一款基准测试工具。不同于简单的方法,这些工具可以提供更加详细的请求性能信息,更为全面而深入地了解请求的情况。当然,以上方法并不是唯一的查询HTTP响应时间的方法,读者如果有其他的方法也可以分享出来。
相关问题拓展阅读:
Linux里面uptime命令作用是什么?
使用方式: uptime
说明: uptime 提供使用者下侍轿面的资讯,不需其他参数:
现在的时间
系统开机运转到现在经锋谈颤过的时间
连线银败的使用者数量
最近一分钟,五分钟和十五分钟的系统负载
# uptime
11:45:25 up 5 days, 13:20, 3 users, load average: 0.00, 0.01, 0.05
uptime内容显示的内容一次是系统时间,开机到现在的天数,用户登录数,以及平均负载。
核心是平均负载,其实就是【单位时间内的活跃进程数】。
2颗,单颗4核CPU为例:
1分钟:10.00 #CPU处理进程1分钟的繁忙程度,忙碌1分钟。
5分钟:8.01 #CPU处理进程5分钟的繁忙程度,忙碌了5分钟
15分钟:5.05 #CPU处理进程15分钟的繁忙程度,忙碌持续15分钟,15分钟内平均值5.
uptime:故障恢复了。
1分钟:1.00 #CPU处理进程1分钟的繁忙程度,忙碌1分钟。
5分钟:8.01 #CPU处理进程5分钟的繁忙程度,忙碌了5分钟
15分钟:5.05 #CPU处理进程15分钟的繁忙程度,忙碌持续15分钟,15分钟内平均值5.
==============================================
总结:15分钟负载值12,是高是低呢
负载数值/总的核心数=1 #开始慢的临界点,实际上1*70%==关注的临界点。
12/8=1.2 大于1就说明有问题。
负载不要超过5,是临界点。
2颗单颗4核CPU,共8核,负载就是8*70%=5左右。
需要关注负载的值:总的核心数*70%=关注的点
==================要掌握的============================
1.平均负载是运行队列中活跃的进程数。
2.平均负载,1,5,15分钟内的负载。
3.需要关注负载的值:总的核心数*70%=关注的点
4.辅助top,ps,uptime,sar,mpstat,pidstat,iostat,排查问题。
5.strace跟踪进程系统调用。
6.记住几个案例(面试讲故事)。
面试官问:
你在工作中遇到过哪些生产故障,是怎么解决的?
更好和数据库相关(负载高),和web相关(PHP进程100%,JAVA内存泄漏)
==================要掌握的============================
***6.平均负载案例分析实战\***
下面,我们以三个示例分别来看这三种情况,并用 stress、mpstat、pidstat 等工具,找出平均负载瞎侍升高的根源。
stress 是 Linux 系统压力测试工具,这里我们用作唤罩异常进程模拟平均负载升高的场景。
mpstat 是多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
#如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包
yum install sysstats -y
yum install stress -y
stress –cpu 8 –io 4 –vm 2 –vm-bytes 128M –timeout 10s
***场景一:CPU 密集型进程\***
1.首先,我们在之一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
# stress –cpu 1 –timeout 600
2.接着,在第二个终端运行 uptime 查看平均负载的变化情况
# 使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高)
# watch -d uptime
*3.最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况*
# -P ALL 表示监控所有CPU,后面数字5 表示间隔5秒后输出一组数据
# mpstat -P ALL 5
#单核CPU,所以只有一个all和0
4.从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。那么,到底是哪个进程导致磨链吵了 CPU 使用率为 100% 呢?可以使用 pidstat 来查询
!(18.Linux系统管理-进程管理.assets/a.png)
# 间隔5秒输出一组数据
# pidstat -u 5 1
#从这里可以明显看到,stress进程的CPU使用率为100%。
– 模拟cpu负载高 `stress –cpu 1 –timeout 100`
– 通过uptime或w 查看 `watch -d uptime`
– 查看整体状态mpstat -P ALL 1 查看每个cpu核心使用率
– 精确到进程: pidstat 1
****场景二:I/O 密集型进程\****
1.首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
# stress –io 1 –timeout 600s #利用sync()
stress –hddhdd-bytes 1g # hd harkdisk 创建进程去进程写
*2.然后在第二个终端运行 uptime 查看平均负载的变化情况:*
# watch -d uptime
18:43:51 up 2 days, 4:27, 3 users, load average: 1.12, 0.65, 0.00
*3.最后第三个终端运行 mpstat 查看 CPU 使用率的变化情况:*
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
# mpstat -P ALL 5
#会发现cpu的与内核打交道的sys占用非常高
*4.那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询*
# 间隔5秒后输出一组数据,-u 表示CPU指标
# pidstat -u 5 1
#可以发现,还是 stress 进程导致的。
– 通过stress 模拟大量进程读写 `stress –hdd 4 `
– 通过w/uptime查看系统负载信息 `watch -d uptime`
– 通过top/mpstat 排查 `mpstat -P ALL 1 或 top 按1`
– 确定是iowati `iostat 1查看整体磁盘读写情况 或iotop -o 查看具体哪个进程读写`
– 根据对应的进程,进行相关处理.
***场景三:大量进程的场景 高并发场景 \***
*当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。*
*1.首先,我们还是使用 stress,但这次模拟的是 4 个进程*
# stress -c 4 –timeout 600
*2.由于系统只有 1 个 CPU,明显比 4 个进程要少得多,因而,系统的 CPU 处于严重过载状态*
*3.然后,再运行 pidstat 来看一下进程的情况:*
# 间隔5秒后输出一组数据
# pidstat -u 5 1
*可以看出,4 个进程在争抢 1 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。*
****分析完这三个案例,我再来归纳一下平均负载与CPU\****
***平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源****
**系统负载的计算和意义**
进程以及子进程和线程产生的计算指令都会让cpu执行,产生请求的这些进程组成”运行队列”,等待cpu执行,这个队列就是系统负载, 系统负载是所有cpu的运行队列的总和.
# w
20:25:48 up 95 days, 9:06, 1 user, load average: 2.92, 0.00, 0.00
//假设当前计算机有4个核心的cpu,当前的负载是2.92
cpu1cpu2cpu3cpu4
2.94/4(个cpu核心) = 73%的cpu资源被使用,剩下27%的cpu计算资源是空想的
//假设当前的计算有2个核心的cpu,当前的负载是2.92
2.92/2 = 146% 已经验证超过了cpu的处理能力
7. 日常故障排查流程(含日志)
– w/uptime, 查看负载
– ps aux/top 看看 cpu百分比, io wait或者是内存占用的高? (三高 cpu,io,内存)
– top检查具体是哪个进程,找出可疑进程
– 追踪这个进程使用情况,做什么的?
– 看看对应**日志**是否有异常
– 系统日志: /var/log/messages(系统通用日志) /var/log/secure(用户登录情况)
– 服务软件的日志
***3.那平均负载为多少时合理\***
*最理想的状态是每个 CPU核心 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。所以在评判平均负载时,首先你要知道系统有几个 CPU核心,这可以通过 top 命令获取,或`grep ‘model name’ /proc/cpuinfo`*
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
– 它没有在等待I/O操作的结果
– 它没有主动进入等待状态(也就是没有调用’wait’)
– 没有被停止(例如:等待终止)
《内容来自老男孩老师的课堂笔记》
关于linux怎么查询请求耗时的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。