
MySQL通透详解架构设计
系统只要能从数据库连接池获取到一个数据库连接,就能执行CRUD。可通过数据库连接将待执行SQL发给MySQL。
大部分 crud boy只知道:
- 执行insert语句后,在表里会多条数据
- 执行update后,会更改表数据
- 执行delete后,会删除表里数据
- 执行select后,会查询表里数据出来
- 要是SQL性能丢人,建几个索引解决
- …
这应该是目前行业内很多工程师对数据库的一个认知,完全当他是个黑盒来建表及执行SQL。
网络连接必须有线程处理
假设数据库服务器的连接池中的某个连接,接收到一条SQL网络请求,请思考:
- 谁负责从这个连接中去监听网络请求?
- 谁负责从网络连接里把请求数据读取出来?
网络连接得有一个线程来监听请求及读取请求数据,比如从网络连接中读取和解析出来一条业务系统发的SQL语句:
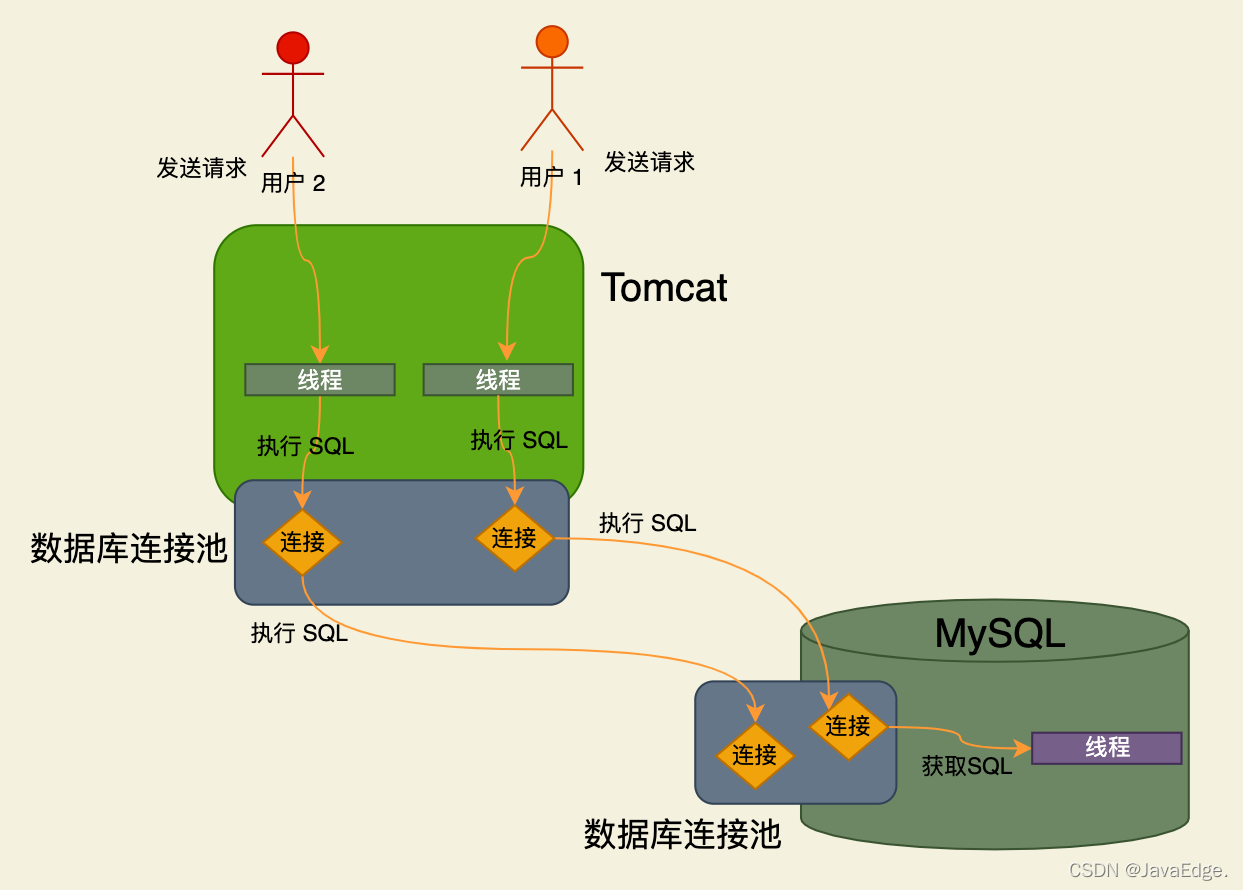
SQL接口
负责处理接收到的SQL语句。
MySQL的工作线程从一个网络连接中读出一个SQL语句后,会如何执行该SQL呢?
MySQL提供了SQL接口(SQL Interface),一套执行SQL语句的接口,专门执行业务系统发送的那些CRUD语句
因此MySQL的工作线程接收到SQL语句之后,就会转交给SQL接口去执行:
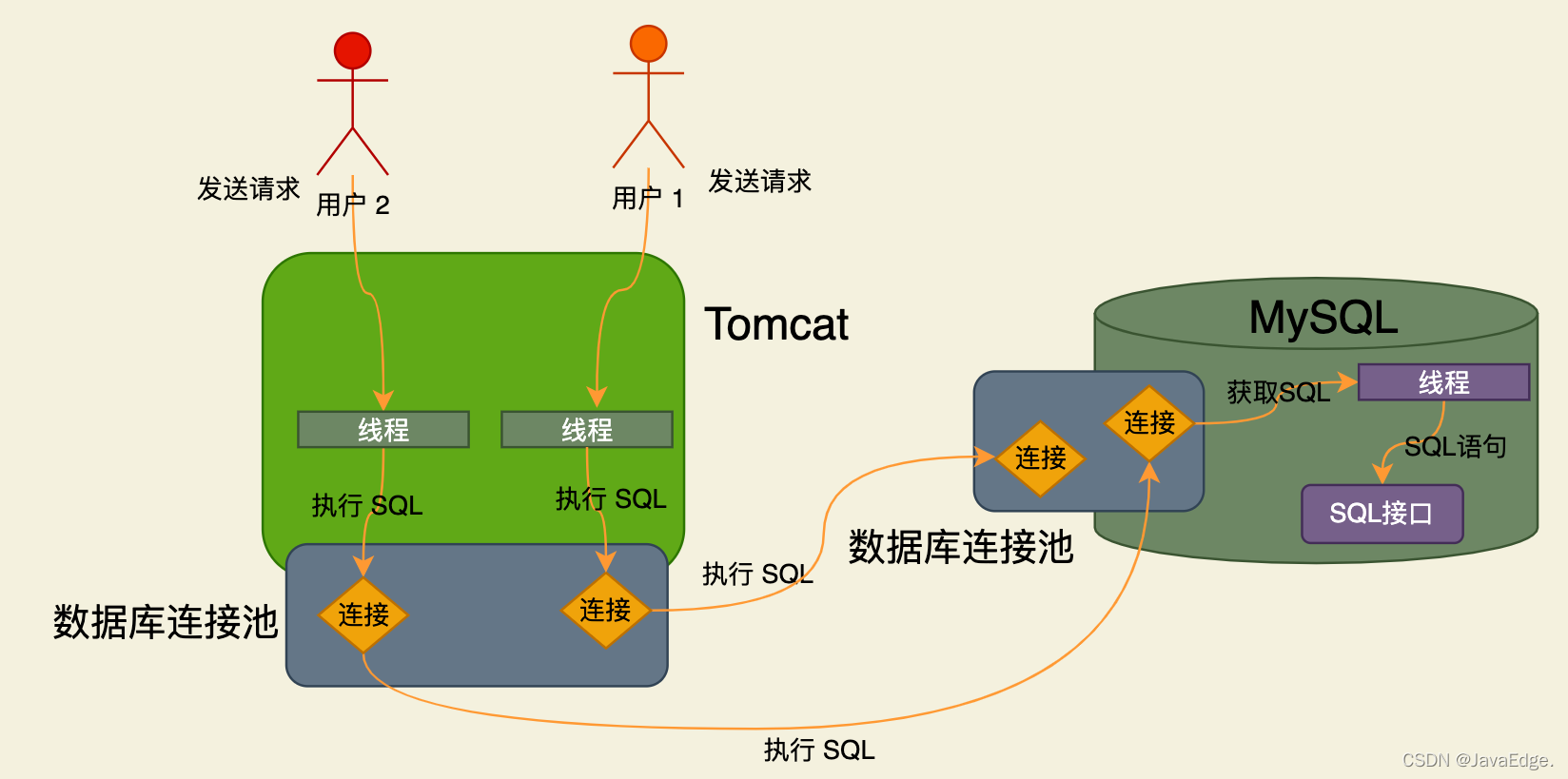
查询解析器
那SQL接口怎么执行SQL语句的?这玩意能懂这些SQL语句?
假设有如下SQL:
select id,name,age from users where id=1
这就需要查询解析器(Parser),负责解析SQL语句,比如对那个SQL拆解成:
- 要从“users”表里查询数据
- 查询“id”字段的值等于1的那行数据
- 对查出来的那行数据要提取里面的“id,name,age”三字段
SQL解析也就是按SQL语法来解析SQL语句意欲何为:
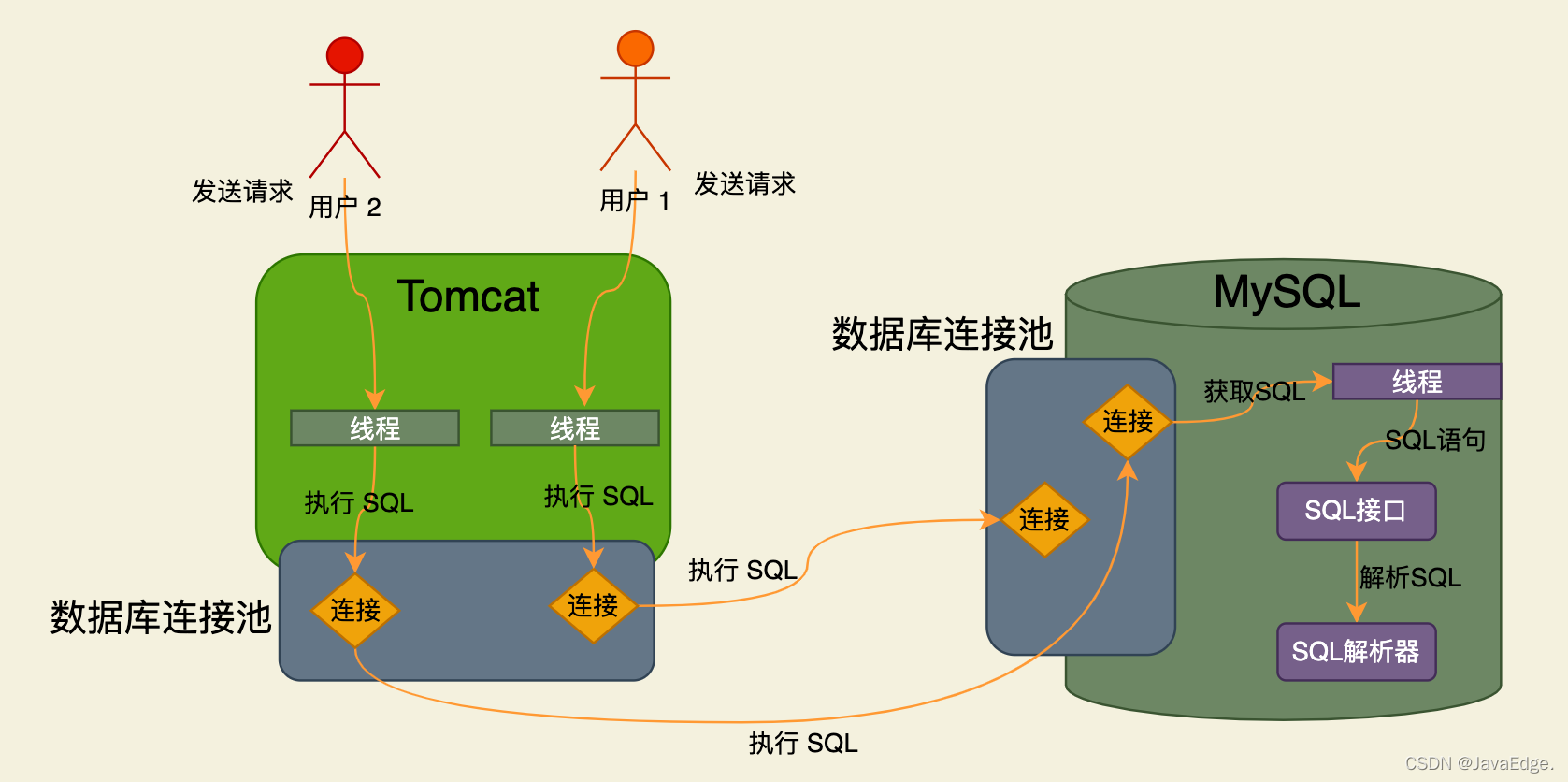
查询优化器
通过解析器知道SQL要干啥了,然后就得找查询优化器(Optimizer)选择一个最优查询路径。
啥叫最优查询路径呢?
之前的那个SQL:从“users”表里查询数据,查“id”字段的值等于1的那行数据,对查出来的那行数据要提取里面的“id,name,age”三个字段。
要完成此事有如下查询路径:
- 直接定位到users表中的id字段等于1的那行数据,查出来那行数据的id、name、age三个字段值
- 先把users表中的每行数据的“id,name,age”三个字段的值都查出来,然后从这批数据里过滤出来“id”字段等于1的那行数据的“id,name,age”三个字段
可见,完成该SQL,两条路径都能实现,那到底选哪个呢?显然第一种性能更好。
所以查询优化器大概就是这个意义,他会针对你的SQL生成查询路径树,选择最优查询路径。
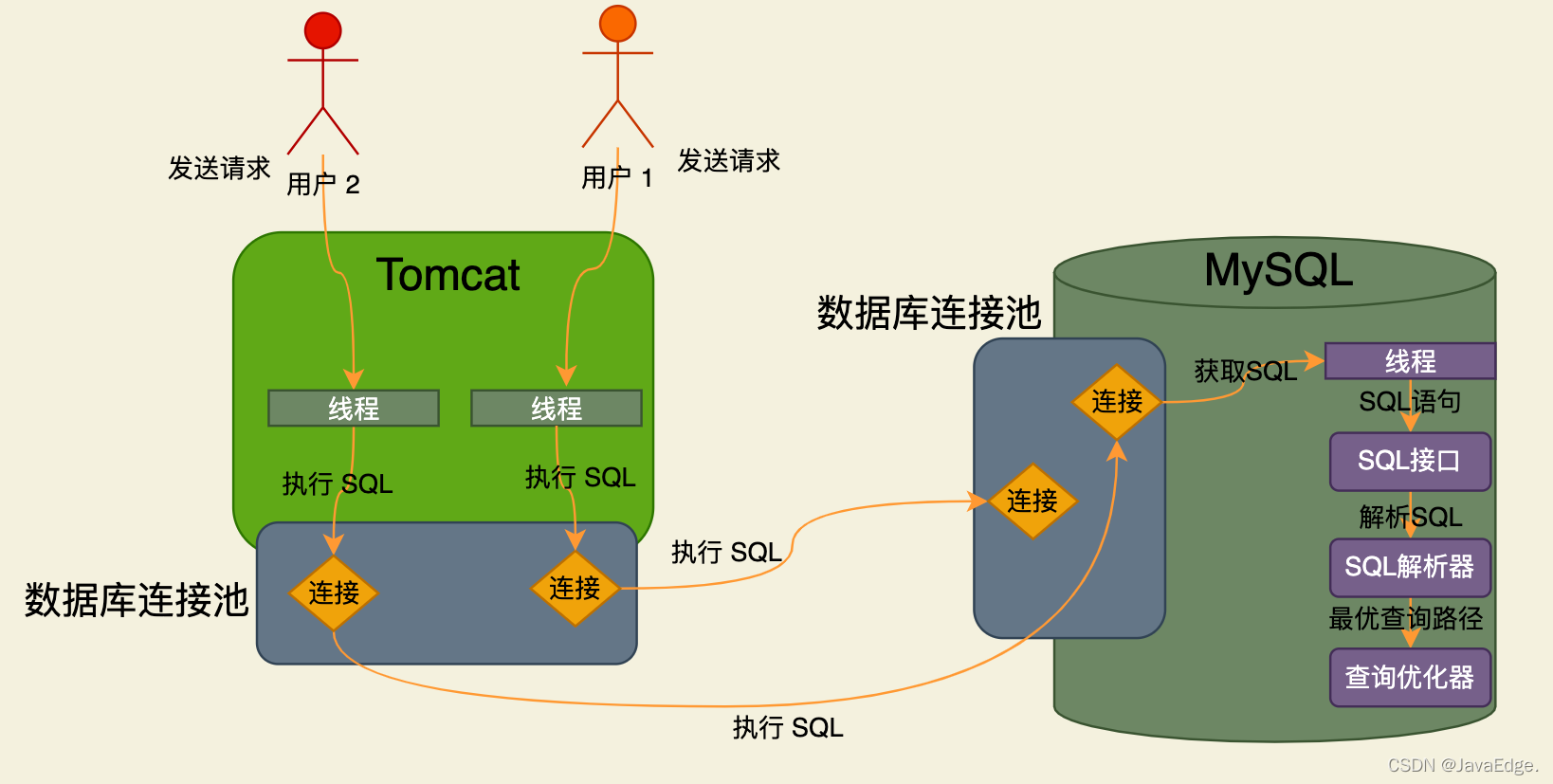
调用存储引擎接口,真正执行SQL语句。
把查询优化器选择的最优查询路径,即到底应该按照一个什么样的顺序和步骤去执行这个SQL语句的计划,把该计划交给底层的存储引擎去真正执行。
假设我们的数据有的存在内存,有的存在磁盘文件,那到底怎么知道
- 哪些数据在内存?
- 哪些在磁盘?
执行时:
- 是更新内存数据?
- 还是更新磁盘数据?
若更新磁盘数据:
- 先查询哪个磁盘文件
- 再更新哪个磁盘文件?
这就需要存储引擎,就是个执行SQL语句的,会按步骤查询内存缓存数据,更新磁盘数 据,查询磁盘数据等,执行此类的一系列的操作:
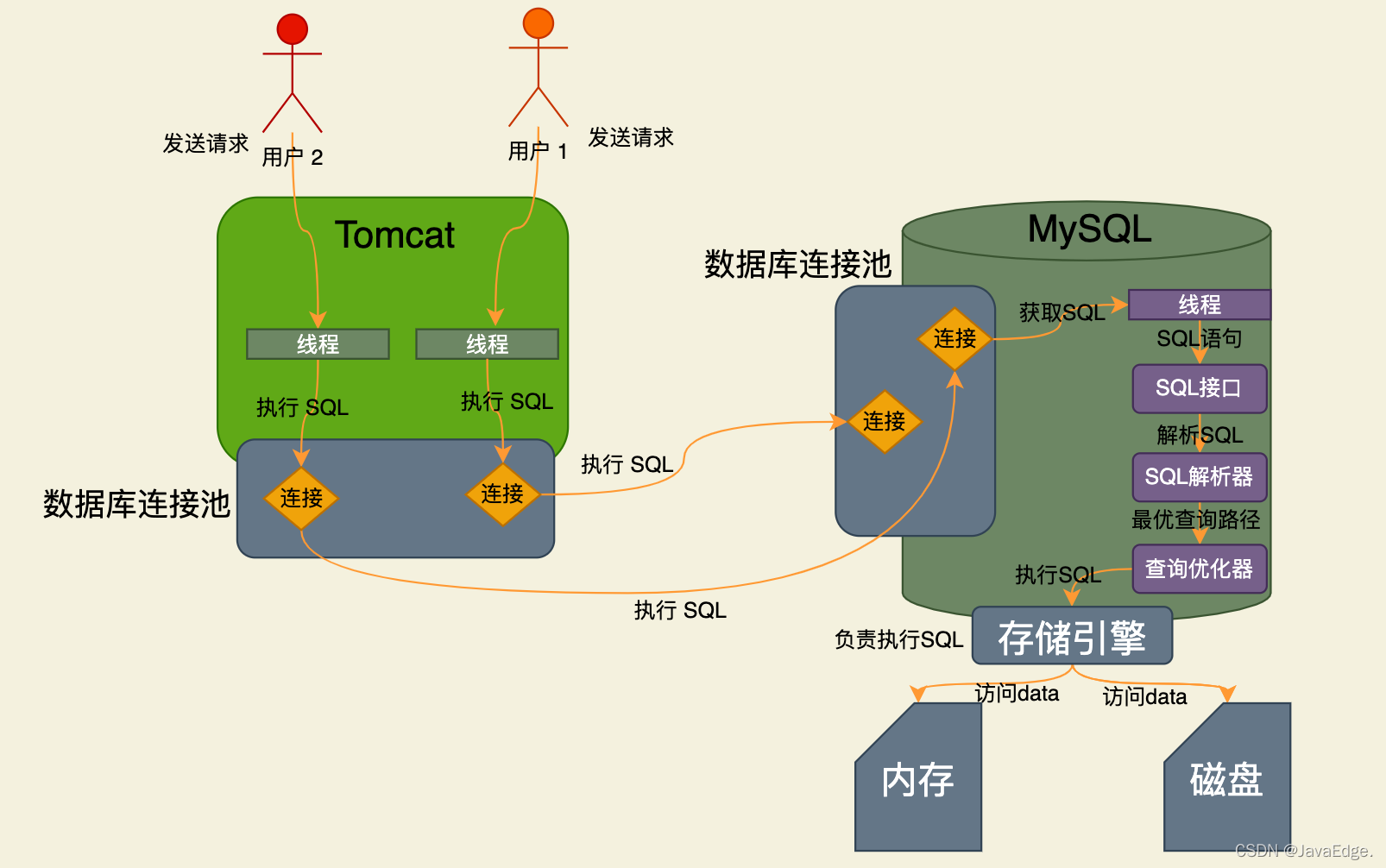
MySQL架构设计中,SQL接口、SQL解析器、查询优化器都是通用的,属于一套组件。但支持各种存储引擎,如InnoDB、MyISAM、Memory等,可以选择具体使用哪种存储引擎来负责执行SQL。
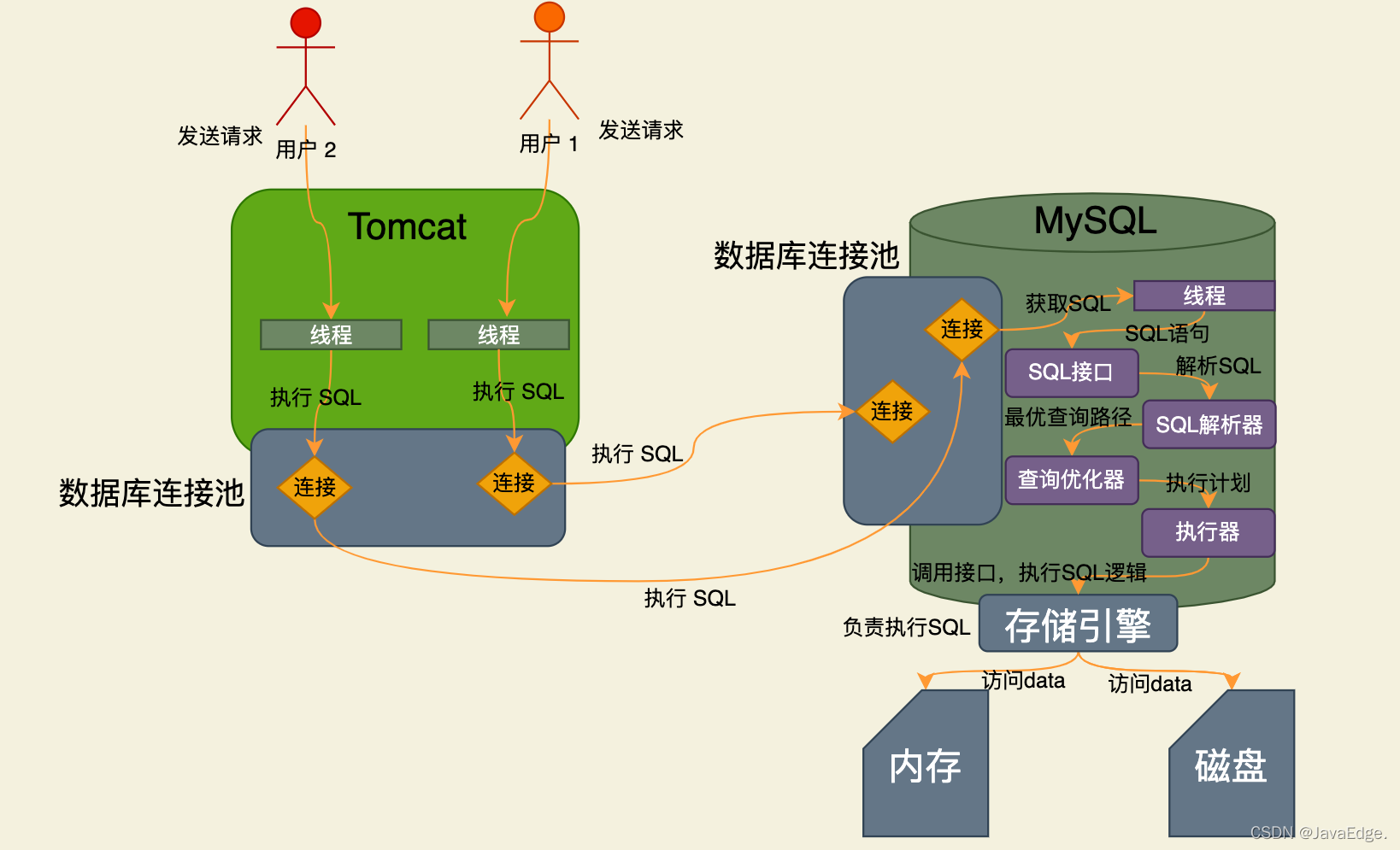
执行器
根据执行计划调用存储引擎的接口。
存储引擎可帮助我们去访问内存及磁盘上的数据,那谁来调存储引擎的接口?
那就是执行器,会根据优化器选择的执行方案,按照一定的顺序和步骤调用存储引擎的接口,执行SQL逻辑。
比如执行器可能先调用存储引擎的一个接口,获取“users”表中的第一行数据,然后判断一下这个数据的“id”字段的值是否等于我们期望的一个值,如果不是的话,那就继续调用存储引擎的接口,去获取“users”表的下一行数据。
也就这套操作,执行器会根据优化器生成的执行计划,不停调用存储引擎的接口们,去完成SQL语句的执行计划,即不停的更新或提取一些数据:
到此这篇关于MySQL通透详解架构设计的文章就介绍到这了,更多相关MySQL 架构设计内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!





