
MySQL中replace into与replace区别详解
本篇为抛砖引玉篇,之前没关注过replace into 与replace 的区别。经过多个场景测试,居然没找到在插入数据的时候两者有什么本质的区别?如果了解详情的伙伴们,请告知留言告知一二,不胜感激!!!
0.故事的背景
【表格结构】
`strategy_type` int DEFAULT NULL,
`user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`status` int DEFAULT NULL,
`destroy_at` datetime DEFAULT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY `xtp_algo_white_list_UN` (`strategy_type`,`user_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
# `strategy_type`,`user_name` 这两个是联合唯一索引,多关注后续需要用到!!!
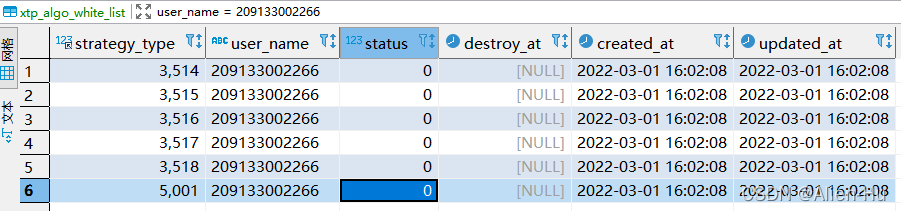
【需求:】
- 根据表格里面, 209133002266账户的数据,重新插入一个用户20220302001, 使得新生成的数据中strategy_type & status & destroy_at 字段与209133002266用户的一致。
- 使用update 一条一条更新也行,但是比较慢。
- 使用replace into 效果会高很多,但是深入研究发现也有一些坑的地方
1.replace into 的使用方法
select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;
# replace into 后面跟表格+需要插入的所有字段名(自动递增字段不用写)
# select 后面选择的字段,如果根据查询结果取值,则写字段名;如果是写死的,则直接写具体值即可
# 可以理解为,第一部分是插入表格的结构,第二部分是你查询的数据结果
2.有唯一索引时—replace into & 与replace 效果
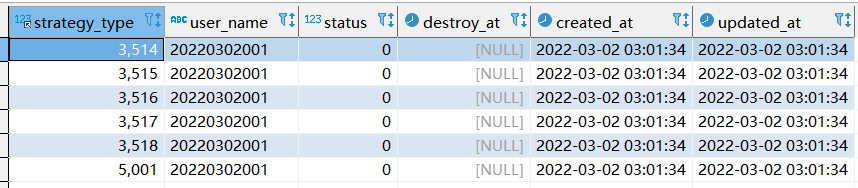
step1: 第一次执行sql情况
select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

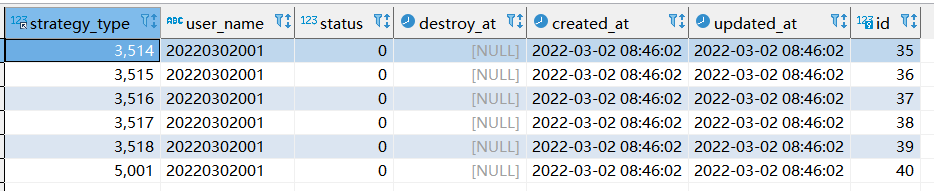
【执行完之后,查询结果如下:】
step2: 第二次执行sql情况

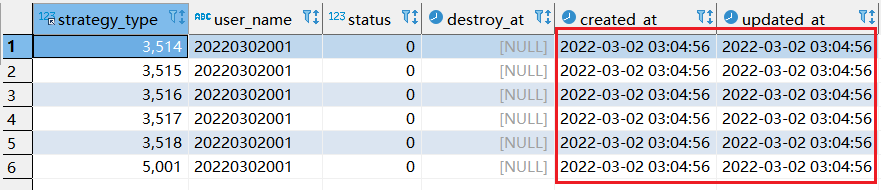
为什么第二次执行的时候,显示update 12行的数据且created at 数据更新了,而第一次会显示update 6行???
1.因为在执行sql的时候,replace into 其实分了两个步骤执行。第一步是将查询到数据转化为新的数据。第二步, 新的数据如果表中已经有相同的内容,则删除掉。如果没有相同的内容,则直接插入新的数据。
2.因如上第一次执行的时候,已经生成一次新数据了,第二次会先删除,再把最新的数据插入进去,最终才显示update 12 行
step3: 第三次执行sql情况
replace xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`)
select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

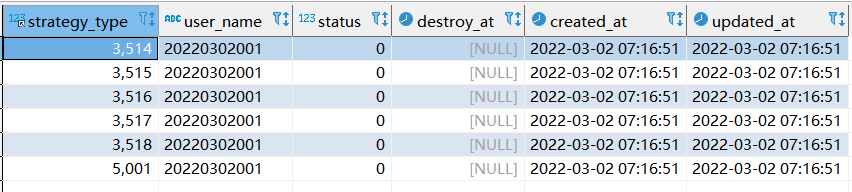
- 最终查看到的情况与第二次执行的sql一样。
- 当新数据已经存在的时候,replace into 与replace是一样的
- 后续删除所有20220302001,执行1次,2次sql,发现replace into 与 replace 效果都是一样的
【总结:】当有唯一索引限制的时候,如果新增的数据会受限于唯一索引,则数据只会插入一次,如果已经存在则会先删除再插入。此时replace into 与replace 效果一样。
3.没有唯一索引时—replace into 与 replace
我们将strategy_type & user_name 联合唯一索引删除,且删除20220302001用户所有数据。最终表格结构如下:
`strategy_type` int DEFAULT NULL,
`user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`status` int DEFAULT NULL,
`destroy_at` datetime DEFAULT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
1).replace函数的具体情况
step1:执行如下replace 对应sql:
select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

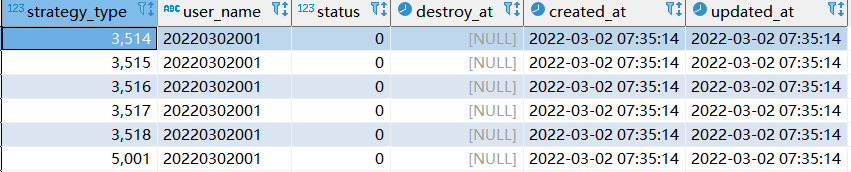
step2:再次执行replace 对应sql:

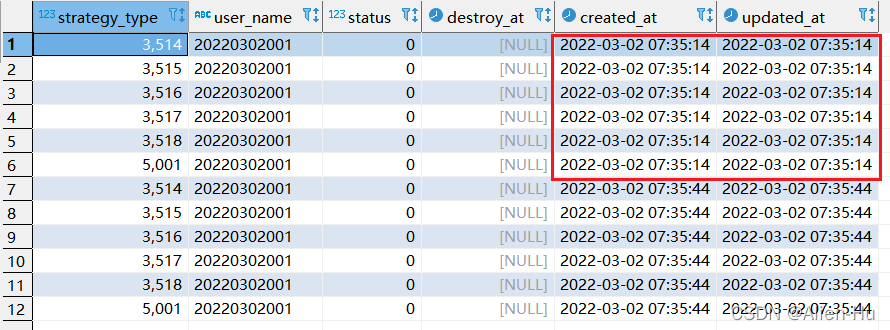
- 第二次执行replace 对应sql ,因为没有唯一索引限制,结果原始数据居然没变动。又重新生成了新的6条数据。
- 如果后续还执行如上的sql,则数据还会继续增加
2).replace into 函数的具体情况
执行之前,先清理数据,将所有20220302001的数据都删除掉
step1:执行如下replace into 对应sql:
select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

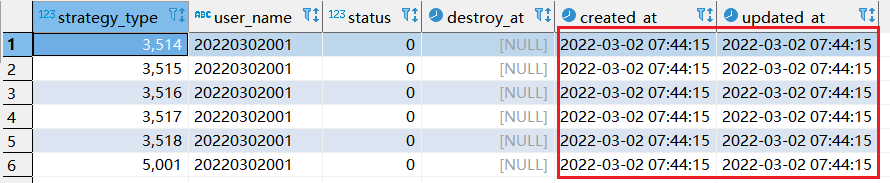
step2:再次执行replace into 对应sql:

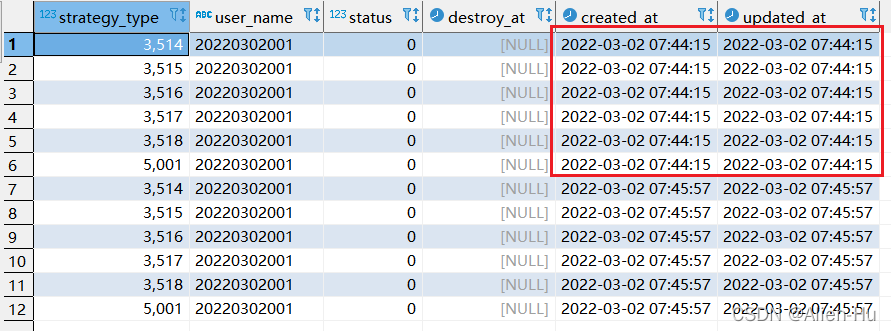
最终发现,没有唯一索引的时候,replace into 与replace 居然一摸一样的效果,都是继续增加数据。
通过以上分析,没看出replace into 与replace 具体有啥区别????有谁知道呢?
4.replace的用法
- 单独replace的作用是替换字段中某数值的显示效果。可以数值中的部分替换、也可以全部替换。
- 如下表格,将user_name的字段,20220302改为"A_20220303"显示,并且新字段叫做new_name显示

到此这篇关于MySQL中replace into与replace区别详解的文章就介绍到这了,更多相关MySQL replace into与replace内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!





