
常用Oracle分析函数大全
Oracle的分析函数功能非常强大,工作这些年来经常用到。这次将平时经常使用到的分析函数整理出来,以备日后查看。
我们拿案例来学习,这样理解起来更容易一些。
1、建表
create table earnings — 打工赚钱表
(
earnmonth varchar2(6), — 打工月份
area varchar2(20), — 打工地区
sno varchar2(10), — 打工者编号
sname varchar2(20), — 打工者姓名
times int, — 本月打工次数
singleincome number(10,2), — 每次赚多少钱
personincome number(10,2) — 当月总收入
)
2、插入实验数据
insert into earnings values(‘200912′,’北平’,’511601′,’大魁’,11,30,11*30);
insert into earnings values(‘200912′,’北平’,’511602′,’大凯’,8,25,8*25);
insert into earnings values(‘200912′,’北平’,’511603′,’小东’,30,6.25,30*6.25);
insert into earnings values(‘200912′,’北平’,’511604′,’大亮’,16,8.25,16*8.25);
insert into earnings values(‘200912′,’北平’,’511605′,’贱敬’,30,11,30*11);
insert into earnings values(‘200912′,’金陵’,’511301′,’小玉’,15,12.25,15*12.25);
insert into earnings values(‘200912′,’金陵’,’511302′,’小凡’,27,16.67,27*16.67);
insert into earnings values(‘200912′,’金陵’,’511303′,’小妮’,7,33.33,7*33.33);
insert into earnings values(‘200912′,’金陵’,’511304′,’小俐’,0,18,0);
insert into earnings values(‘200912′,’金陵’,’511305′,’雪儿’,11,9.88,11*9.88);
insert into earnings values(‘201001′,’北平’,’511601′,’大魁’,0,30,0);
insert into earnings values(‘201001′,’北平’,’511602′,’大凯’,14,25,14*25);
insert into earnings values(‘201001′,’北平’,’511603′,’小东’,19,6.25,19*6.25);
insert into earnings values(‘201001′,’北平’,’511604′,’大亮’,7,8.25,7*8.25);
insert into earnings values(‘201001′,’北平’,’511605′,’贱敬’,21,11,21*11);
insert into earnings values(‘201001′,’金陵’,’511301′,’小玉’,6,12.25,6*12.25);
insert into earnings values(‘201001′,’金陵’,’511302′,’小凡’,17,16.67,17*16.67);
insert into earnings values(‘201001′,’金陵’,’511303′,’小妮’,27,33.33,27*33.33);
insert into earnings values(‘201001′,’金陵’,’511304′,’小俐’,16,18,16*18);
insert into earnings values(‘201001′,’金陵’,’511305′,’雪儿’,11,9.88,11*9.88);
commit;
3、查看实验数据
select * from earnings;
查询结果如下
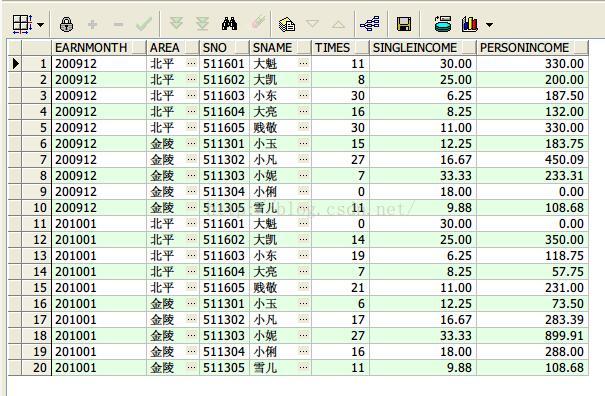
4、sum函数按照月份,统计每个地区的总收入
select earnmonth, area, sum(personincome)
from earnings
group by earnmonth,area;
查询结果如下
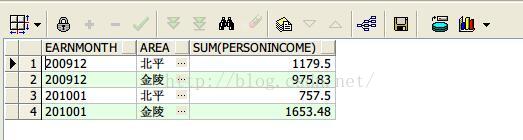
5、rollup函数按照月份,地区统计收入
select earnmonth, area, sum(personincome)
from earnings
group by rollup(earnmonth,area);
查询结果如下
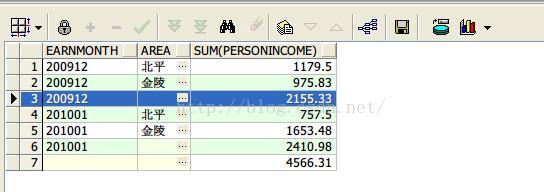
6、cube函数按照月份,地区进行收入汇总
select earnmonth, area, sum(personincome)
from earnings
group by cube(earnmonth,area)
order by earnmonth,area nulls last;
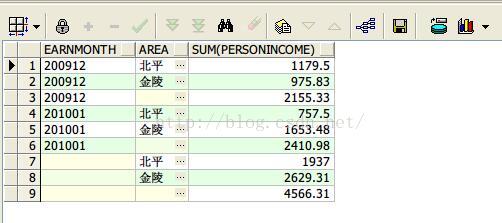
查询结果如下
小结:sum是统计求和的函数。
group by 是分组函数,按照earnmonth和area先后次序分组。
以上三例都是先按照earnmonth分组,在earnmonth内部再按area分组,并在area组内统计personincome总合。
group by 后面什么也不接就是直接分组。
group by 后面接 rollup 是在纯粹的 group by 分组上再加上对earnmonth的汇总统计。
group by 后面接 cube 是对earnmonth汇总统计基础上对area再统计。
另外那个 nulls last 是把空值放在最后。
rollup和cube区别:
如果是ROLLUP(A, B, C)的话,GROUP BY顺序
(A、B、C)
(A、B)
(A)
最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),GROUP BY顺序
(A、B、C)
(A、B)
(A、C)
(A)
(B、C)
(B)
(C)
最后对全表进行GROUP BY操作。
7、grouping函数在以上例子中,是用rollup和cube函数都会对结果集产生null,这时候可用grouping函数来确认
该记录是由哪个字段得出来的
grouping函数用法,带一个参数,参数为字段名,结果是根据该字段得出来的就返回1,反之返回0
select decode(grouping(earnmonth),1,’所有月份’,earnmonth) 月份,
decode(grouping(area),1,’全部地区’,area) 地区, sum(personincome) 总金额
from earnings
group by cube(earnmonth,area)
order by earnmonth,area nulls last;
查询结果如下
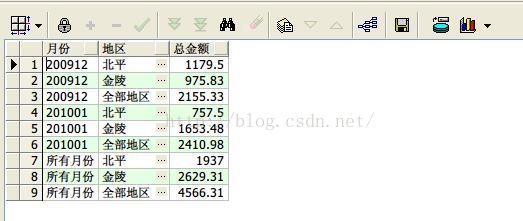
8、rank() over开窗函数
按照月份、地区,求打工收入排序
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
rank() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下
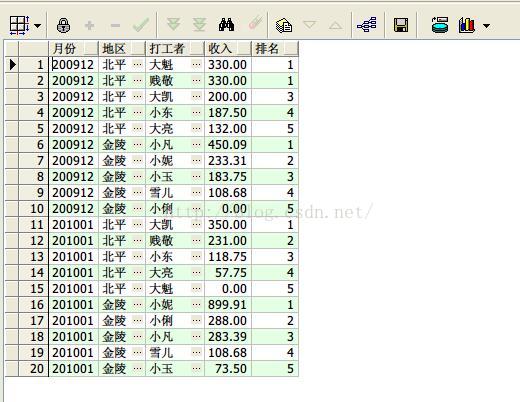
9、dense_rank() over开窗函数按照月份、地区,求打工收入排序2
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
dense_rank() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下
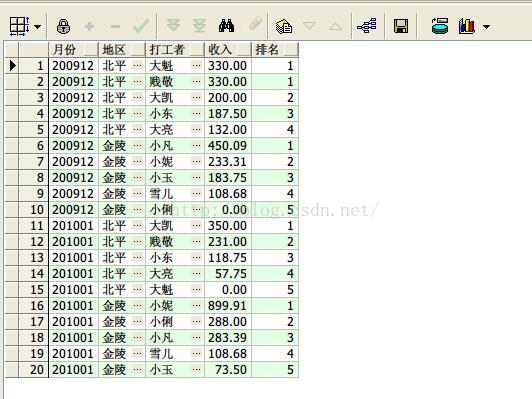
10、row_number() over开窗函数按照月份、地区,求打工收入排序3
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
row_number() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下
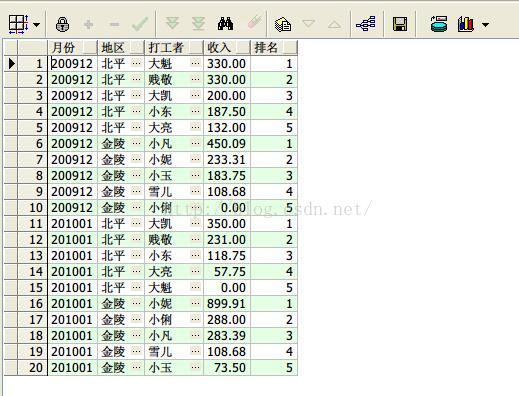
通过(8)(9)(10)发现rank,dense_rank,row_number的区别:
结果集中如果出现两个相同的数据,那么rank会进行跳跃式的排名,
比如两个第二,那么没有第三接下来就是第四;
但是dense_rank不会跳跃式的排名,两个第二接下来还是第三;
row_number最牛,即使两个数据相同,排名也不一样。
11、sum累计求和根据月份求出各个打工者收入总和,按照收入由少到多排序
select earnmonth 月份,area 地区,sname 打工者,
sum(personincome) over (partition by earnmonth,area order by personincome) 总收入
from earnings;
查询结果如下
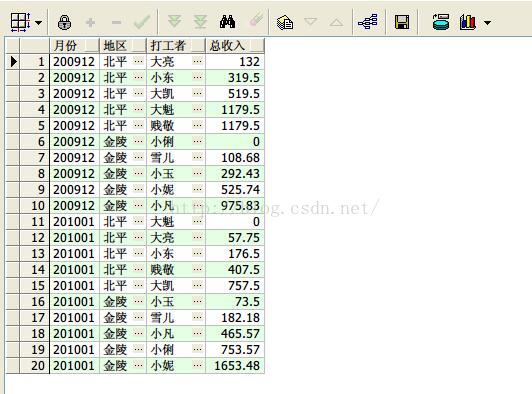
12、max,min,avg和sum函数综合运用按照月份和地区求打工收入最高值,最低值,平均值和总额
select distinct earnmonth 月份, area 地区,
max(personincome) over(partition by earnmonth,area) 最高值,
min(personincome) over(partition by earnmonth,area) 最低值,
avg(personincome) over(partition by earnmonth,area) 平均值,
sum(personincome) over(partition by earnmonth,area) 总额
from earnings;
查询结果如下
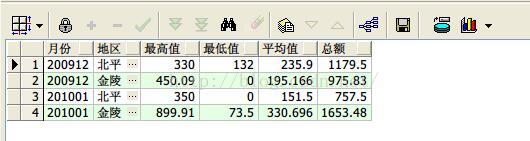
13、lag和lead函数求出每个打工者上个月和下个月有没有赚钱(personincome大于零即为赚钱)
select earnmonth 本月,sname 打工者,
lag(decode(nvl(personincome,0),0,’没赚’,’赚了’),1,0) over(partition by sname order by earnmonth) 上月,
lead(decode(nvl(personincome,0),0,’没赚’,’赚了’),1,0) over(partition by sname order by earnmonth) 下月
from earnings;
查询结果如下
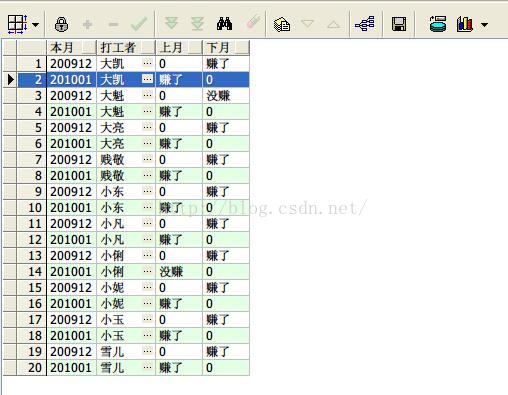
说明:Lag和Lead函数可以在一次查询中取出某个字段的前N行和后N行的数据(可以是其他字段的数据,比如根据字段甲查询上一行或下两行的字段乙)
语法如下:
lag(value_expression [,offset] [,default]) over ([query_partition_clase] order_by_clause);
lead(value_expression [,offset] [,default]) over ([query_partition_clase] order_by_clause);
其中:
value_expression:可以是一个字段或一个内建函数。
offset是正整数,默认为1,指往前或往后几点记录.因组内第一个条记录没有之前的行,最后一行没有之后的行,default就是用于处理这样的信息,默认为空。
再讲讲所谓的开窗函数,依本人遇见,开窗函数就是 over([query_partition_clase] order_by_clause)。比如说,我采用sum求和,rank排序等等,但是我根据什么来呢?over提供一个窗口,可以根据什么什么分组,就用partition by,然后在组内根据什么什么进行内部排序,就用 order by。
以上所述是小编给大家介绍的常用Oracle分析函数大全,大家如有疑问可以留言,或者联系站长。感谢亲们支持!!!





