基于Redis实现多表对象缓存技术(redis缓存多表对象)
基于Redis实现多表对象缓存技术
在现代Web应用程序中,对象缓存技术已成为非常重要的一部分。缓存可以显著提高系统性能并降低负载,并在大流量的情况下有效提高吞吐量。然而,单一的缓存存储通常仅适用于键值存储,并不方便用于对象缓存。因此,我们需要一个更高级别的缓存存储,可以用于多表对象缓存。这时,Redis可以为我们提供一种解决方案。
Redis是一个高性能的开源非关系型数据库,它支持广泛的键值数据结构,并且具有很好的可扩展性,易于部署。它可以轻松地处理高速或大量的读写请求,并支持从内存中永久存储和检索数据,从而提高了系统的性能和可靠性。基于Redis的多表对象缓存技术可以有效地提高Web应用程序的性能。
对象缓存技术的主要优势在于缓存数据的快速读取,可以显著缩短从数据库中检索数据的时间。以下是基于Redis的多表对象缓存技术的实现方式:
我们需要创建一个Redis连接,并且在该连接下创建一个对象存储。可以使用Python Redis库建立连接:
import redis
redis_conn = redis.Redis(host='localhost', port=6379, db=0)
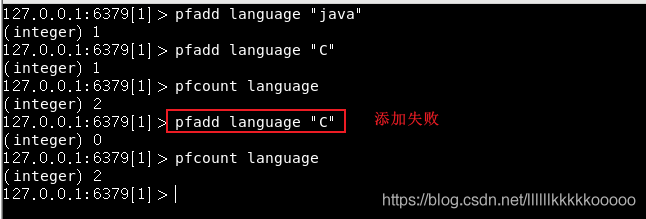
接下来,我们需要建立内存缓存。Redis内置了一个哈希表,用于储存键值对,并且具有O(1)的常数时间复杂度。对象储存在哈希表中,用哈希表中的一个键代表对象的唯一ID,用哈希表中对应键的值为对象的序列化字符串表示。
这里,我们使用Redis的哈希表来存储对象:
class RedisCache:
def __init__(self, redis_conn): self._redis_conn = redis_conn
def set(self, key, value): self._redis_conn.hset('objects', key, pickle.dumps(value))
def get(self, key): pickled_obj = self._redis_conn.hget('objects', key)
if pickled_obj: return pickle.loads(pickled_obj)
return None
值得注意的是,这里我们使用Python中的pickle序列化库,实现对象的序列化和反序列化。
我们现在拥有了一个基于Redis的多表对象缓存技术。通过将对象储存于缓存中,我们可以在每次需要读取对象数据时检查缓存是否有对象的副本。如果有,我们就可以使用缓存中的对象,而不必从数据库或其他数据源中检索数据。这可以大大减少我们的负载和等待时间,以便更快地响应用户请求。
基于Redis的多表对象缓存技术可以有效地改善Web应用程序的性能。Redis作为一种高性能的非关系型数据库,可以轻松地处理大流量的请求,并支持内存中的数据永久储存。因此,在构建Web应用程序时,我们应该对Redis进行深入了解,并使用基于Redis的多表对象缓存技术来提高系统的性能和稳定性。