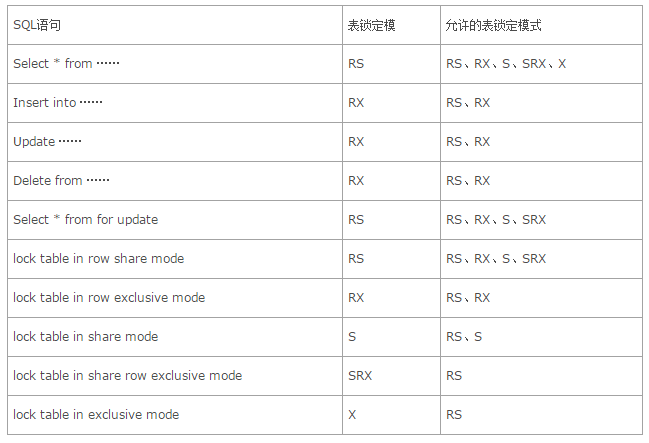
极大改善性能的Redis缓存适用于哪些场景(redis缓存适用哪些地方)
Redis是一款基于内存的高性能NoSQL数据库,具备快速读写能力和丰富的数据结构,因此广泛应用于缓存、消息队列、计数器、分布式锁等场景。其中,Redis缓存作为其最常见的应用场景之一,可极大地改善应用程序的性能。那么,Redis缓存适用于哪些场景呢?
一、适用场景
1.高并发读取场景:Redis内存中存储数据,读写速度非常快,可轻松应对高并发读取场景,减轻传统关系型数据库的压力。
2.海量数据缓存场景:Redis支持的数据类型丰富,包括字符串、哈希、列表、集合、有序集合等,且存储在内存中,通过分片或集群方式可支持海量数据缓存场景。
3.热点数据缓存场景:Redis支持过期时间设置,可将热点数据缓存起来,提高数据访问速度和负载能力。
4.分布式架构场景:Redis自带的分布式锁和计数器等功能,可在分布式架构场景下实现数据的一致性和同步。
二、实现方法
Redis的缓存实现开发人员需要注意以下几点:
1.缓存策略:Redis的缓存策略可以采用LRU(最近最少使用)等算法,开发人员需要根据应用场景选择最合适的算法。
2.缓存失效:Redis默认没有设置过期时间的条目将永远存在于内存中,如果不及时删除将造成内存溢出,因此开发人员需要在使用时设置缓存失效时间。
3.缓存穿透:缓存穿透指请求的key不存在于缓存中,每次都会直接请求数据库,导致缓存无效。如果出现缓存穿透问题,可以采用布隆过滤器等技术进行解决。
4.缓存雪崩:缓存雪崩指缓存大量的数据在同一时间失效,导致服务器压力过大倒塌。开发人员可以采用分布式锁等方式进行解决。
针对以上问题,下面提供一些Redis缓存实现的示例代码:
1.缓存策略:
使用LRU算法进行缓存,在Redis中设置maxmemory和maxmemory-policy参数,如下所示:
config set maxmemory 1GB
config set maxmemory-policy LRU
2.缓存失效:
使用expire命令设置缓存失效时间,如下所示:
set key value
expire key 60 //60秒后自动过期
3.缓存穿透:
使用布隆过滤器,将查询的key映射成二进制位,并设置多个哈希函数,查询时只需要判断key是否在布隆过滤器中存在,如下所示:
def bloom_filter(fn):
def wrapper(*args, **kwargs):
key = args[1]
if cache.get(key) is None:
value = fn(*args, **kwargs)
cache.set(key, value)
else:
value = cache.get(key)
return value
return wrapper
4.缓存雪崩:
使用分布式锁方式实现,如下所示:
def distribute_lock(fn):
def wrapper(*args, **kwargs):
lock_key = ‘lock:%s’ % fn.__name__
if cache.get(lock_key) is None:
cache.set(lock_key, True, ex=60)
value = fn(*args, **kwargs)
cache.delete(lock_key)
else:
time.sleep(0.1)
return wrapper(*args, **kwargs)
return value
以上是Redis缓存实现的一些方法和示例代码,开发人员需要根据具体业务场景选择最适合的方法。通过Redis缓存的应用,可以极大地改善应用程序的性能,提高用户体验,增加系统吞吐量,降低服务器负载压力。