
postgresql 数据库基础 之 array_to_string和array的用法讲解
有三张表,分别如下:
select * from vehicle
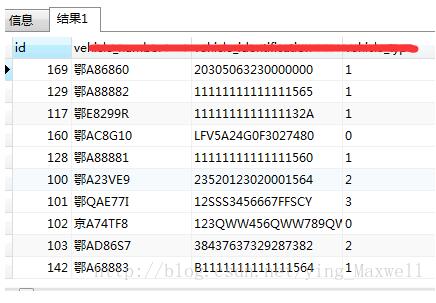
select * from station
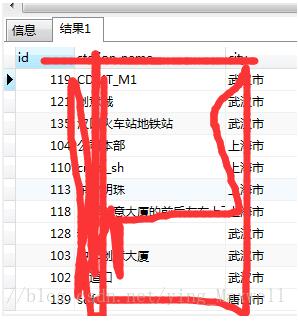
select * from vehicle_station
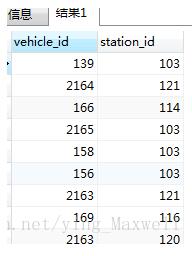
需求:
vehicle和station表示多对多的关系,需要把vehicle表对应的station表的第二字段查出来放到一个字段,如果对应多条,用逗号隔开放到一个字段。
解决方案:
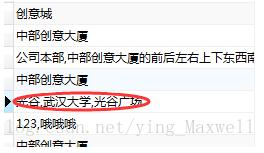
SELECT v.*, array_to_string(ARRAY (SELECT station_name FROM station WHERE ID IN (SELECT station_id FROM vehicle_station WHERE vehicle_id = v. ID)),’,’) station_names FROM vehicle v
结果如下:
补充:Postgres array 数组类型详细使用
德哥这篇文章写的很不错,在相关函数部分,尤其是 array_upper,array_lower 部分,有我自己的一些解释。
ARRAY类型包含几个重要的特征
维度
也就是几维数组, 不管怎么赋值, ARRAY最终必须是个矩阵.
例1 :
ARRAY[1,2,3,4] 是一维数组,
ARRAY[[1,2],[3,4],[5,6]] 是二维数组
例2 :
ARRAY[[‘digoal’,’zhou’],[‘a’,’b’,c’]] 是错误的. 因为第二个维度中的第一个array有2个元素, 而第二个array有3个元素. 不是一个矩阵. 个数必须一致.
同时类型也必须一致
例3 :
ARRAY[[‘digoal’,’zhou’],[1,2]] 是错误的. 因为[‘digoal’,’zhou’]是text[]类型, 而[1,2]是int[]类型.
元素
一维数组ARRAY[1,2,3,4] 中的4个元素分别是 1, 2, 3, 4. 这些int型的值.
二维数组ARRAY[[1,2],[3,4],[5,6]] 中的第一维度有3个元素是 ARRAY[1,2] , ARRAY[3,4] , ARRAY[5,6] 这些int[]类型的值. 第二个维度的第一个subscript的元素有两个, 分别是1,2 . 第二个subscript 分别是3,4. 第三个subscript分别是5,6.
元素之间的分隔符, 除了box类型是分号;, 其他类型的分隔符都是逗号,.
扩展性
一维数组可以扩展, 二维数组无法扩展.
subscript
访问ARRAY中的元素需要提供subscript值. 默认是从1开始编号. 除非赋值的时候强制指定subscript
例1 :
ARRAY[[1,2],[3,4],[5,6]] as a
a[1][1] = 1;
a[1][2] = 2;
a[2][1] = 3;
a[2][2] = 4;
a[3][1] = 5;
a[3][2] = 6;
a第一个[]表示第一维度, 里面的数字代表第一维度中要访问的subscript,
a第二个[]表示第二维度, 里面的数字代表第二维度中要访问的subscript,
另外也可以访问ARRAY的slice.
例2 :
a[1:2][1:1] = {{1},{3}}
第一个[]中的1表示低位subscript, 2表示高位subscript值.
第二个[]中左边的1表示低位subscript, 右边的1表示高位subscript值.
a[2:3][1:2] = {{3,4},{5,6}}
分片的另一种写法, 只要其中的一个维度用了分片写法, 其他的维度如果没有使用分片写法, 默认视为高位
如a[2:3][2] 等同于 a[2:3][1:2]
接下来讲解一下ARRAY类型的几个常用函数 :
array_dims, 返回的是各个维度中的低位subscript和高位subscript, 如下 :
digoal=> select array_dims(ARRAY[[1,2,3,4,5],[6,7,8,9,10]]);
array_dims
———+–
[1:2][1:5]
array_length, 返回的是array中指定维度的长度或元素个数, 如下 :
digoal=> select array_length(ARRAY[[1,2,3,4,5],[6,7,8,9,10]], 1);
array_length
——-+——
2
digoal=> select array_length(ARRAY[[1,2,3,4,5],[6,7,8,9,10]], 2);
array_length
——–+—–
5
注意:array_lower 和 array_upper 返回值都是下标 ,默认从1开始的下标。
array_lower, 返回的是ARRAY中指定维度的低位subscript值, 如下 :
digoal=> select array_lower(ARRAY[[1,2,3,4,5],[6,7,8,9,10]], 2);
array_lower
——–+—-
1
下面就是强制指定subscript值了,
digoal=> select array_lower(‘[-3:-2]={1,2}’::int[], 1);
array_lower
———+—-
-3
array_upper, 返回的是ARRAY中指定维度的高位subscript值, 如下 :
digoal=> select array_upper(ARRAY[[1,2,3,4,5],[6,7,8,9,10]], 2);
array_upper
——–+—-
5
下面就是强制指定subscript值了,
digoal=> select array_upper(‘[-3:-2]={1,2}’::int[], 1);
array_upper
——–+—-
-2
array_prepend, 用于在一维数组的前面插入元素, 如下
digoal=> select array_prepend(‘digoal’, ARRAY[‘francs’,’david’]);
array_prepend
——————-+—
{digoal,francs,david}
array_append, 用于在一维数组的后面插入元素, 如下
digoal=> select array_append(ARRAY[‘francs’,’david’], ‘digoal’);
array_append
—————+——-
{francs,david,digoal}
array_cat, 用于两个相同维度的数组的连接, 或者一个n维数组和一个n+1维数组的连接, 如下
digoal=> select array_cat(ARRAY[‘francs’], ARRAY[‘digoal’,’david’]);
array_cat
—————-+——
{francs,digoal,david}
digoal=> select array_cat(ARRAY[‘francs’], ARRAY[[‘digoal’]]);
array_cat
—————–+—
{{francs},{digoal}}
generate_subscripts, 用于按顺序返回ARRAY的指定维度的subscript(s)值, 如下 :
正向返回第一维度的subscript值.
digoal=> select generate_subscripts(a, 1) from (select ARRAY[‘a’,’b’,’c’,’d’] as a) t;
generate_subscripts
—————+—–
1
2
3
4
反向返回第一维度的subscript值.
digoal=> select generate_subscripts(a, 1, true) from (select ARRAY[‘a’,’b’,’c’,’d’] as a) t;
generate_subscripts
—————–+–
4
3
2
1
digoal=> select generate_subscripts(a, 1) from (select ‘[-5:-1]={1,2,3,4,5}’::int[] as a) t;
generate_subscripts
—————+—–
-5
-4
-3
-2
-1
digoal=> select generate_subscripts(a, 1, true) from (select ‘[-5:-1]={1,2,3,4,5}’::int[] as a) t;
generate_subscripts
—————+—–
-1
-2
-3
-4
-5
多维数组的第二维度,
digoal=> select generate_subscripts(a, 2) from (select ‘[-5:-4][2:4]={{1,2,3},{4,5,6}}’::int[] as a) t;
generate_subscripts
—————+—–
2
3
4
接下来讲解一下ARRAY类型的操作符
digoal=> select typname,oid from pg_type where typname=’anyarray’;
typname | oid
———-+——
anyarray | 2277
操作符如下 :
digoal=> select oprname,oprleft,oprright,oprresult,oprcode,oprrest,oprjoin from pg_operator where oprleft=2277 or oprright=2277;
oprname | oprleft | oprright | oprresult | oprcode | oprrest | oprjoin
———+———+———-+———–+—————-+————-+—————–
|| | 2277 | 2283 | 2277 | array_append | – | –
|| | 2283 | 2277 | 2277 | array_prepend | – | –
|| | 2277 | 2277 | 2277 | array_cat | – | –
= | 2277 | 2277 | 16 | array_eq | eqsel | eqjoinsel
<> | 2277 | 2277 | 16 | array_ne | neqsel | neqjoinsel
< | 2277 | 2277 | 16 | array_lt | scalarltsel | scalarltjoinsel
> | 2277 | 2277 | 16 | array_gt | scalargtsel | scalargtjoinsel
<= | 2277 | 2277 | 16 | array_le | scalarltsel | scalarltjoinsel
>= | 2277 | 2277 | 16 | array_ge | scalargtsel | scalargtjoinsel
&& | 2277 | 2277 | 16 | arrayoverlap | areasel | areajoinsel
@> | 2277 | 2277 | 16 | arraycontains | contsel | contjoinsel
<@ | 2277 | 2277 | 16 | arraycontained | contsel | contjoinsel
(12 rows)
【注意】
– PostgreSQL中对ARRAY类型的维度没有限制, 如int[]并不代表只能存储一维数组, 其实可以存储任意维度的ARRAY值.
– PostgreSQL中对ARRAY类型中元素的个数也没有限制, 如int[10] , 不代表只能存储10个元素.可以超出.
例如 :
digoal=> create table array_test (id int[2]);
CREATE TABLE
digoal=> insert into array_test values (ARRAY[[1,2,3,4,5],[6,7,8,9,10]]);
INSERT 0 1
这个例子中元素的个数和维度都超出了int[2]的限制,但是并没有报错,而且数据已经存储进去了.
digoal=> select * from array_test ;
id
———————+——
{{1,2,3,4,5},{6,7,8,9,10}}
手册上的解释如下 :
However, the current implementation ignores any supplied array size limits, i.e., the behavior is the same as for arrays of unspecified length.
The current implementation does not enforce the declared number of dimensions either. Arrays of a particular element type are all considered to be of the same type, regardless of size or number of dimensions. So, declaring the array size or number of dimensions in CREATE TABLE is simply documentation; it does not affect run-time behavior.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。





