
PostgreSQL 数据库ROW_NUMBER() OVER()的用法
语法:
ROW_NUMBER() OVER( [ PRITITION BY col1] ORDER BY col2[ DESC ] )
解释:
ROW_NUMBER()为返回的记录定义个行编号, PARTITION BY col1 是根据col1分组,ORDER BY col2[ DESC ]是根据col2进行排序。
举例:
postgres=# create table student(id serial,name character varying,course character varying,score integer);
CREATE TABLE
postgres=#
postgres=# \d student
Table “public.student”
Column | Type | Modifiers
——–+——————-+———————————————-
id | integer | not null default nextval(‘student_id_seq’::regclass)
name | character varying |
course | character varying |
score | integer |
insert into student (name,course,score) values(‘周润发’,’语文’,89);
insert into student (name,course,score) values(‘周润发’,’数学’,99);
insert into student (name,course,score) values(‘周润发’,’外语’,67);
insert into student (name,course,score) values(‘周润发’,’物理’,77);
insert into student (name,course,score) values(‘周润发’,’化学’,87);
insert into student (name,course,score) values(‘周星驰’,’语文’,91);
insert into student (name,course,score) values(‘周星驰’,’数学’,81);
insert into student (name,course,score) values(‘周星驰’,’外语’,88);
insert into student (name,course,score) values(‘周星驰’,’物理’,68);
insert into student (name,course,score) values(‘周星驰’,’化学’,83);
insert into student (name,course,score) values(‘黎明’,’语文’,85);
insert into student (name,course,score) values(‘黎明’,’数学’,65);
insert into student (name,course,score) values(‘黎明’,’外语’,95);
insert into student (name,course,score) values(‘黎明’,’物理’,90);
insert into student (name,course,score) values(‘黎明’,’化学’,78);
1. 根据分数排序
postgres=# select *,row_number() over(order by score desc)rn from student;
id | name | course | score | rn
—-+——–+——–+——-+—-
2 | 周润发 | 数学 | 99 | 1
13 | 黎明 | 外语 | 95 | 2
6 | 周星驰 | 语文 | 91 | 3
14 | 黎明 | 物理 | 90 | 4
1 | 周润发 | 语文 | 89 | 5
8 | 周星驰 | 外语 | 88 | 6
5 | 周润发 | 化学 | 87 | 7
11 | 黎明 | 语文 | 85 | 8
10 | 周星驰 | 化学 | 83 | 9
7 | 周星驰 | 数学 | 81 | 10
15 | 黎明 | 化学 | 78 | 11
4 | 周润发 | 物理 | 77 | 12
9 | 周星驰 | 物理 | 68 | 13
3 | 周润发 | 外语 | 67 | 14
12 | 黎明 | 数学 | 65 | 15
(15 rows)
rn是给我们的一个排序。
2. 根据科目分组,按分数排序
postgres=# select *,row_number() over(partition by course order by score desc)rn from student;
id | name | course | score | rn
—-+——–+——–+——-+—-
5 | 周润发 | 化学 | 87 | 1
10 | 周星驰 | 化学 | 83 | 2
15 | 黎明 | 化学 | 78 | 3
13 | 黎明 | 外语 | 95 | 1
8 | 周星驰 | 外语 | 88 | 2
3 | 周润发 | 外语 | 67 | 3
2 | 周润发 | 数学 | 99 | 1
7 | 周星驰 | 数学 | 81 | 2
12 | 黎明 | 数学 | 65 | 3
14 | 黎明 | 物理 | 90 | 1
4 | 周润发 | 物理 | 77 | 2
9 | 周星驰 | 物理 | 68 | 3
6 | 周星驰 | 语文 | 91 | 1
1 | 周润发 | 语文 | 89 | 2
11 | 黎明 | 语文 | 85 | 3
(15 rows)
3. 获取每个科目的最高分
postgres=# select * from(select *,row_number() over(partition by course order by score desc)rn from student)t where rn=1;
id | name | course | score | rn
—-+——–+——–+——-+—-
5 | 周润发 | 化学 | 87 | 1
13 | 黎明 | 外语 | 95 | 1
2 | 周润发 | 数学 | 99 | 1
14 | 黎明 | 物理 | 90 | 1
6 | 周星驰 | 语文 | 91 | 1
(5 rows)
4. 每个科目的最低分也是一样的
postgres=# select * from(select *,row_number() over(partition by course order by score)rn from student)t where rn=1;
id | name | course | score | rn
—-+——–+——–+——-+—-
15 | 黎明 | 化学 | 78 | 1
3 | 周润发 | 外语 | 67 | 1
12 | 黎明 | 数学 | 65 | 1
9 | 周星驰 | 物理 | 68 | 1
11 | 黎明 | 语文 | 85 | 1
(5 rows)
只要在根据科目排序的时候按低到高顺序排列就好了。
补充:SQL:postgresql中为查询结果增加一个自增序列之ROW_NUMBER () OVER ()的使用
举例说明:
SELECT ROW_NUMBER
() OVER ( ORDER BY starttime DESC ) “id”,
starttime AS “text”,
starttime
FROM
warning_products
WHERE
pid_model = ‘结果’
AND starttime IS NOT NULL
GROUP BY
starttime
在这一段代码中:
查询语句就不说了, select …from…where
GROUP BY的作用:
这一段代码执行的结果是:
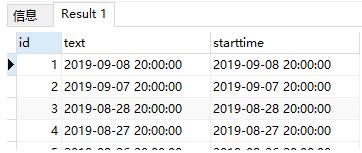
如果将GROUP BY删除,那么执行结果为:
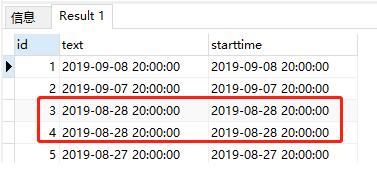
可以看到查询出了两个相同starttime数据.
由此得出:
GROUP BY的作用是分类汇总.也就是说,查询结果中,starttime每一种查询结果只有一个
GROUP BY的作用:
如果将DESC换成
() OVER ( ORDER BY starttime ASC ) “id”,
则运行结果为:
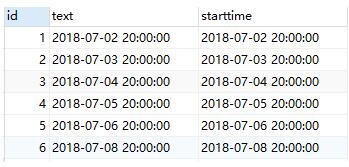
相比可以发现,ORDER BY的作用为进行排序.
按照某种要求进行固定的排序
ROW_NUMBER () OVER() “id”
先来看一下,如果把这一段删掉,运行结果:
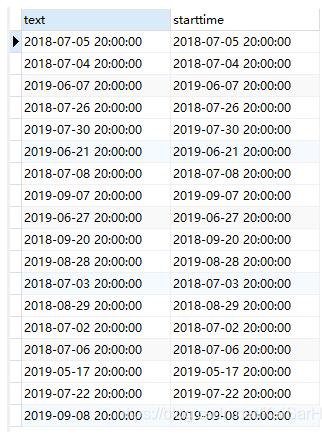
加上呢?

明显的对比,我们为最终的查询结果增加了一列自增的id序列(这里id可以改名,”id”改为其他的即可)
由此得到结论,在执行带有row_number() over() “xx”的SQL语句时候,代码会先执行查询语句,然后执行over中的命令,最后为结果增加一列自增的序列.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。





