
mysql 数据库乱码字符集 latin1 characters 转换为 UTF8方法
背景:目前正在进行业务重构,需要对使用MySQL的业务库表进行重新设计,在迁移时,遇到了中文字符乱码问题(源库表的默认编码是LATIN1,新库表的默认编码为UTF8),故重新学习了下MySQL编码和解码相关知识,并整理了在遭遇乱码时的一些常用技巧。
比如我下面一张表是省市区的编码存储,导入之后数据库变成如下的乱码:
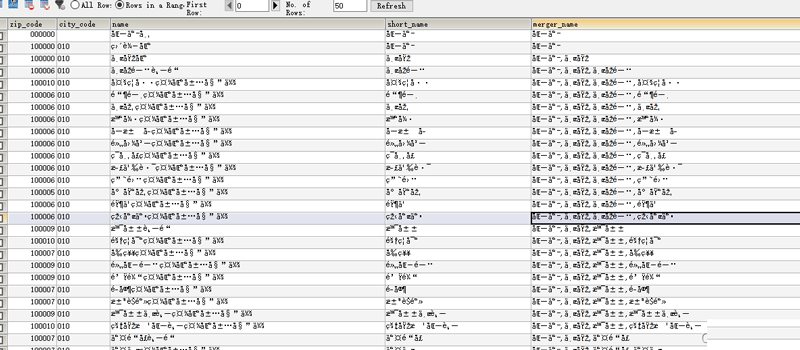
这个实际上是latin1字符编码。
如果我们直接查的话,那么需要转换一下:
select id,parent_code,area_code,CONVERT(CAST(CONVERT(name USING LATIN1) AS BINARY) USING UTF8) from cnarea_2020 where parent_code =’110000000000′ or parent_code =’110101001000′
可以看到如下:
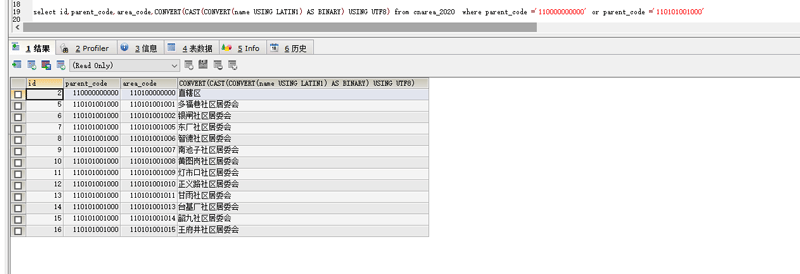
已经转成tf8的编码了,已经正常了!
如果我们要使用查询的字段里面包含乱码,我们可以这样使用:
select * from (select id,parent_code,area_code,CONVERT(CAST(CONVERT(name USING LATIN1) AS BINARY) USING UTF8) as name from cnarea_2020 where city_code =’010′) as t where t.name like ‘%王府井%’
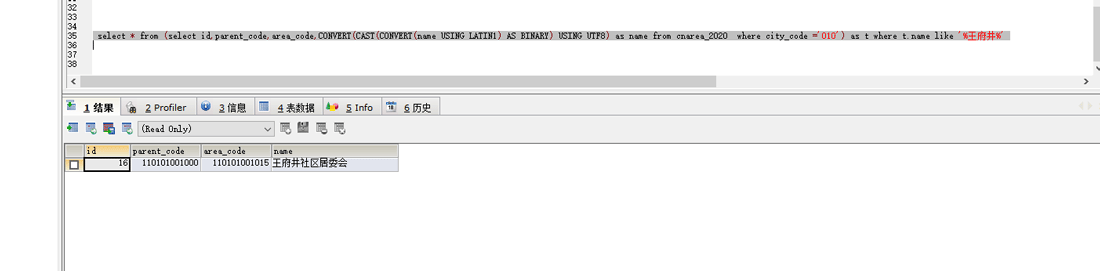
也就是先把查询的目标转成utf8,然后再进行查询.
当然了,以上是在迁移后,库中是乱码的情况下,进行操作的,那我们需要把编码转成utf8这样不用去改写代码,免去不必要的麻烦!
处理前的编码如下:
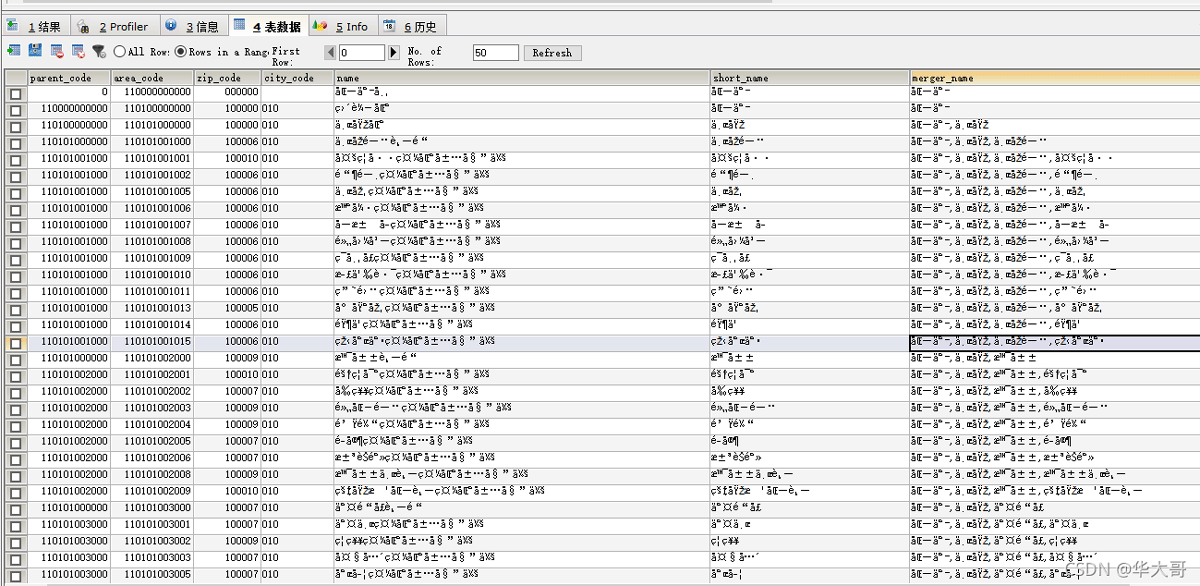
使用如下的操作:
UPDATE cnarea_2020 SET
name=convert(cast(convert(name using latin1) as binary) using utf8),
short_name=convert(cast(convert(short_name using latin1) as binary) using utf8),
merger_name=convert(cast(convert(merger_name using latin1) as binary) using utf8)
WHERE 1=1
name=convert(cast(convert(name using latin1) as binary) using utf8),
short_name=convert(cast(convert(short_name using latin1) as binary) using utf8),
merger_name=convert(cast(convert(merger_name using latin1) as binary) using utf8)
WHERE 1=1
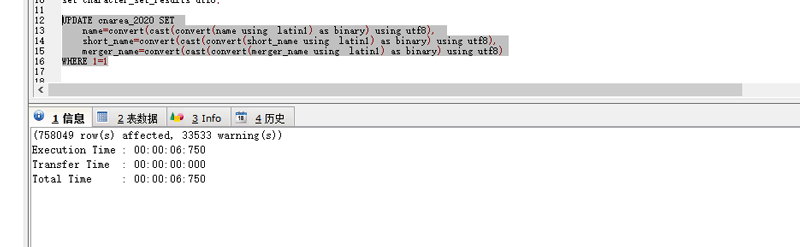
处理后的编码如下:
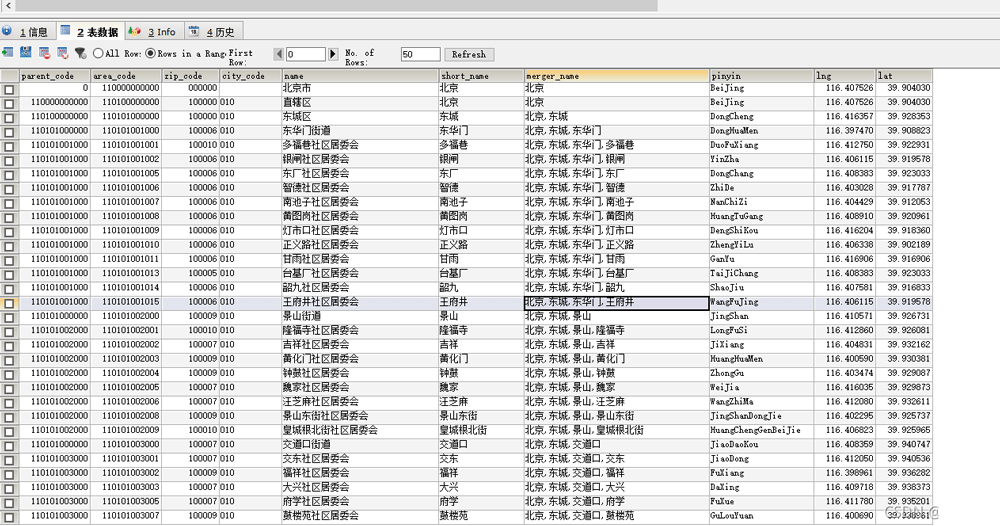
这个时候可以直接查询,不用进行转换了!
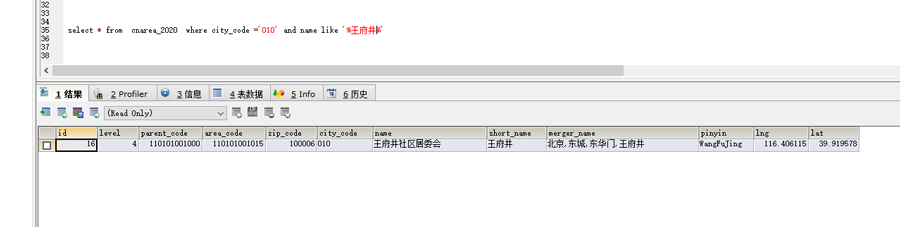
现在已经是正常的编码了,迁移就成功了,不用再去改代码来处理了!
到此这篇关于mysql 乱码字符 latin1 characters 转换为 UTF8详情的文章就介绍到这了,更多相关mysql 乱码转为 UTF8内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!





