
mongodb增量备份脚本的实现和原理详解
前言
mongodb的副本集架构,主库和从库的数据相同步,如果主库的机器坏掉,没什么关系,从库上还有相同的副本数据。但如果某人恶意操作或误操作,一下子批量删除或drop整个库,这样主库和从库的数据都会没有,造成巨大损失。因此,对mongodb数据库定期备份是非常重要的。备份如果每次都全量备份,会消耗大量时间,并且对 mongodb性能也有影响,从而需要能增量备份。mongodb的增量备份网上没有现成的工具,故仔细研究了下写了个脚本。
mongodb集群架构时,从库是通过异步复制主库的Oplog文件,从而达到与主库的同步。
Oplog 记录了MongoDB数据库的更改操作信息,其保存在local库的oplog.rs表,在集群架构才存在,单机不会有,故增量备份不能在单机下使用。 oplog有大小限制,超过指定大小,新的记录会覆盖旧的操作记录。
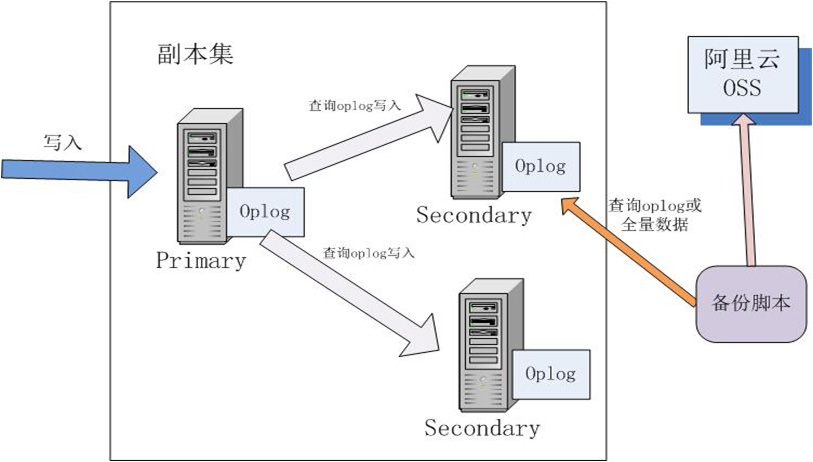
mongodb增量备份原理
如何将某段时间的oplog下载下来,我拼接好的例子:
mongodump -h 127.0.0.1 --port 27117 -d local -c oplog.rs -u admin -p --authenticationDatabase admin -q '{ts:{$gt:{$timestamp:{t:1451355000,i:1}},$lt:{$timestamp:{t:1451357430,i:1}}},ns:/^test_db\\./}' -o oplog_backup
上述是导出1451355000-1451357430时间之间的oplog,导出oplog需要切换到admin权限账户。
原理很简单,但具体实现还是需要很多考虑,具体看代码。脚本在一个周期内(如一星期)先备份一次全量数据库,后面每次进行增量备份。脚本地址:http://git.oschina.net/passer/mongodb_backup_script
增量脚本执行时的流程
- 读取上一个周期执行信息判断是否需要创建新的周期
- 获得mongodb上oplog最近记录的时间点current timestamp position
- 从本地读取上一次执行时mongodb的oplog时间点
- dump导出全量数据或增量oplog文件到本地,增量oplog文件的导出范围是 上次oplog记录点到最新时间内的oplog文件
- 保存步骤2获取的current timestamp position到本地,作为下一次执行步骤3中的时间点
- 进行压缩
- 上传到oss
- 删除本地备份文件
全量脚本执行时的流程
- 备份mongodb数据库到本地
- 进行压缩
- 上传到oss
- 检验oss与本地文件的大小是否相同
- 删除本地备份文件
恢复时脚本执行的流程
- 从oss上下载指定周期的备份文件到本地
- 对全量文件和增量oplog的zip文件进行解压
- 用 mongorestore对全量文件进行导入
- 用 mongorestore –oplogReplay 分别对各时间段的oplog文件进行导入
总结
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
