
关于MongoDB谨防索引seek的效率问题详析
背景
最近线上的一个工单分析服务一直不大稳定,监控平台时不时发出数据库操作超时的告警。
运维兄弟沟通后,发现在每天凌晨1点都会出现若干次的业务操作失败,而数据库监控上并没有发现明显的异常。
在该分析服务的日志中发现了某个数据库操作产生了 SocketTimeoutException。
开发同学一开始希望通过调整 MongoDB Java Driver 的超时参数来规避这个问题。
但经过详细分析之后,这样是无法根治问题的,而且超时配置应该如何调整也难以评估。
下面是关于对这个问题的分析、调优的过程。
初步分析
从出错的信息上看,是数据库的操作响应超时了,此时客户端配置的 SocketReadTimeout 为 60s。
那么,是什么操作会导致数据库 60s 还没能返回呢?
业务操作
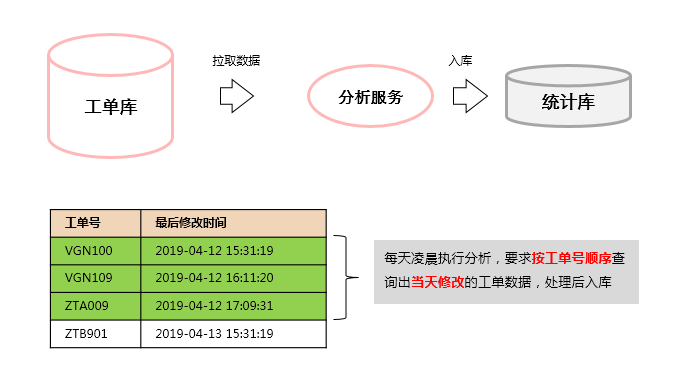
左边的数据库是一个工单数据表(t_work_order),其中记录了每张工单的信息,包括工单编号(oid)、最后修改时间(lastModifiedTime)
分析服务是Java实现的一个应用程序,在每天凌晨1:00 会拉取出前一天修改的工单信息(要求按工单号排序)进行处理。
由于工单表非常大(千万级),所以在处理时会采用分页的做法(每次取1000条),使用按工单号翻页的方式:
第一次拉取
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)},
“oid”: {$exists: true}})
.sort({“oid”:1}).limit(1000)
第二次拉取,以第一次拉取的最后一条记录的工单号作为起点
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)},
“oid”: {$exists: true, $gt: “VXZ190”}})
.sort({“oid”:1}).limit(1000)
..
根据这样的查询,开发人员给数据表使用的索引如下:
db.t_work_order.ensureIndexes({
“oid” : 1,
“lastModifiedTime” : -1
})
尽管该索引与查询字段基本是匹配的,但在实际执行时却表现出很低的效率:
第一次拉取时间非常的长,经常超过60s导致报错,而后面的拉取时间则会快一些
为了精确的模拟该场景,我们在测试环境中预置了小部分数据,对拉取记录的SQL执行Explain:
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)}
“oid”: {$exists: true}})
.sort({“oid”:1}).limit(1000)
.explain(“executionStats”)
输出结果如下
“nReturned” : 1000,
“executionTimeMillis” : 589,
“totalKeysExamined” : 136661,
“totalDocsExamined” : 1000,…
“indexBounds” : {
“oid” : [
“[MinKey, MaxKey]”
],
“lastModifiedTime” : [
“(new Date(1554806697106), new Date(1554803097106))”
]
},
“keysExamined” : 136661,
“seeks” : 135662,
在执行过程中发现,检索1000条记录,居然需要扫描 13.6 W条索引项!
其中,几乎所有的开销都花费在了 一个seeks操作上了。
索引seeks的原因
官方文档对于 seeks 的解释如下:
The number of times that we had to seek the index cursor to a new position in order to complete the index scan.
翻译过来就是:
seeks 是指为了完成索引扫描(stage),执行器必须将游标定位到新位置的次数。
我们都知道 MongoDB 的索引是B+树的实现(3.x以上),对于连续的叶子节点扫描来说是非常快的(只需要一次寻址),那么seeks操作太多则表示整个扫描过程中出现了大量的寻址(跳过非目标节点)。
而且,这个seeks指标是在3.4版本支持的,因此可以推测该操作对性能是存在影响的。
为了探究 seeks 是怎么产生的,我们对查询语句尝试做了一些变更:
去掉 exists 条件
exists 条件的存在是因为历史问题(一些旧记录并不包含工单号的字段),为了检查exists查询是否为关键问题,修改如下:
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)}
})
.sort({“oid”:1}).limit(1000)
.explain(“executionStats”)
执行后的结果为:
“nReturned” : 1000,
“executionTimeMillis” : 1533,
“totalKeysExamined” : 272322,
“totalDocsExamined” : 272322,
…“inputStage” : {
“stage” : “FETCH”,
“filter” : {
“$and” : [
{
“lastModifiedTime” : {
“$lt” : ISODate(“2019-04-09T10:44:57.106Z”)
}
},
{
“lastModifiedTime” : {
“$gt” : ISODate(“2019-04-09T09:44:57.106Z”)
}
}
]
},…
“indexBounds” : {
“oid” : [
“[MinKey, MaxKey]”
],
“lastModifiedTime” : [
“[MaxKey, MinKey]”
]
},
“keysExamined” : 272322,
“seeks” : 1,
这里发现,去掉 exists 之后,seeks 变成了1次,但整个查询扫描了 27.2W 条索引项! 刚好是去掉之前的2倍。
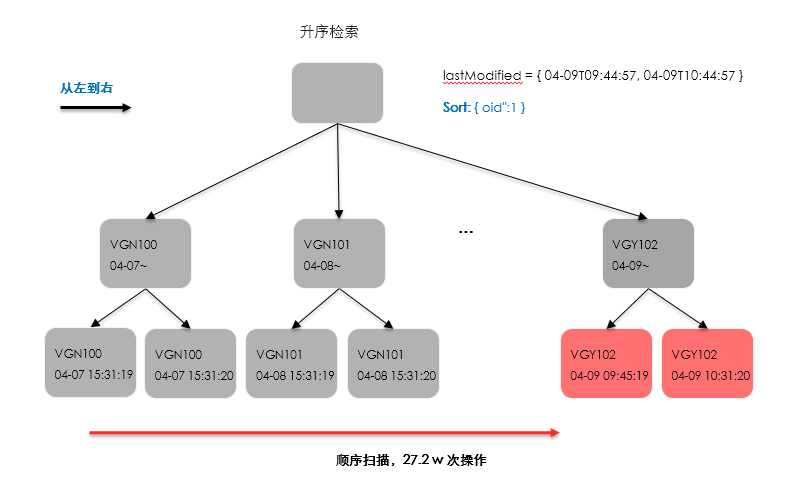
seeks 变为1次说明已经使用了叶节点顺序扫描的方式,然而由于扫描范围非常大,为了找到目标记录,会执行顺序扫描并过滤大量不符合条件的记录。
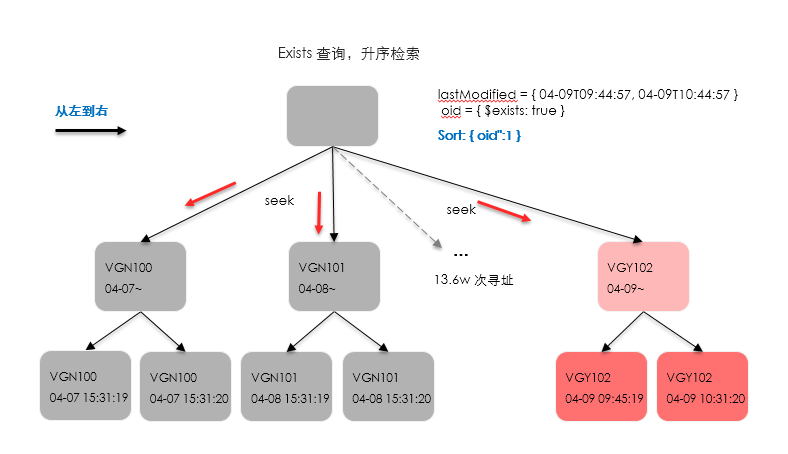
在 FETCH 阶段出现了 filter可说明这一点。与此同时,我们检查了数据表的特征:同一个工单号是存在两条记录的!于是可以说明:
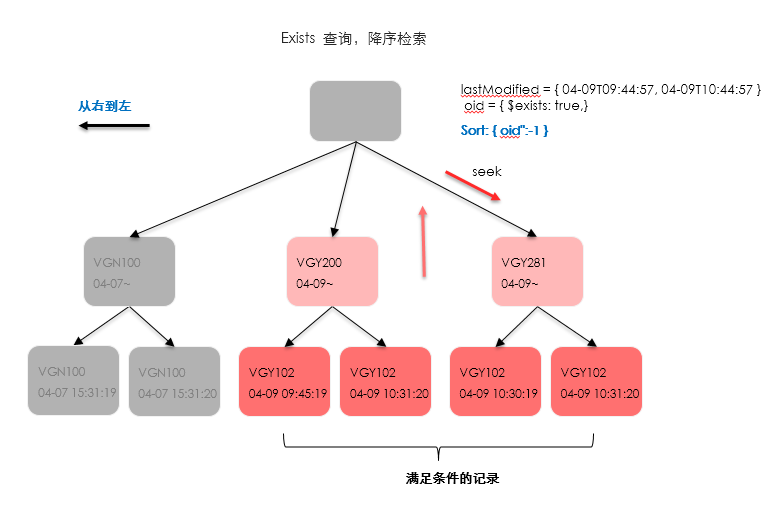
在存在exists查询条件时,执行器会选择按工单号进行seeks跳跃式检索,如下图:
在不存在exists条件的情况下,执行器选择了叶节点顺序扫描的方式,如下图:
gt 条件和反序
除了第一次查询之外,我们对后续的分页查询也进行了分析,如下:
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)},
“oid”: {$exists: true, $gt: “VXZ190”}})
.sort({“oid”:1}).limit(1000)
.explain(“executionStats”)
上面的语句中,主要是增加了$gt: “VXZ190″这一个条件,执行过程如下:
“nReturned” : 1000,
“executionTimeMillis” : 6,
“totalKeysExamined” : 1004,
“totalDocsExamined” : 1000,
…
“indexBounds” : {
“oid” : [
“(\”VXZ190\”, {})”
],
“lastModifiedTime” : [
“(new Date(1554806697106), new Date(1554803097106))”
]
},
“keysExamined” : 1004,
“seeks” : 5,
可以发现,seeks的数量非常少,而且检索过程只扫描了1004条记录,效率是很高的。
那么,是不是意味着在后面的数据中,满足查询的条件的记录非常密集呢?
为了验证这一点,我们将一开始第一次分页的查询做一下调整,改为按工单号降序的方式(从后往前扫描):
db.t_work_order.find({
“lastModifiedTime”:{
$gt: new Date(“2019-04-09T09:44:57.106Z”),
$lt: new Date(“2019-04-09T10:44:57.106Z”)},
“oid”: {$exists: true}})
.sort({“oid”:-1}).limit(1000)
.explain(“executionStats”)
新的”反序查询语句”的执行过程如下:
“nReturned” : 1000,
“executionTimeMillis” : 6,
“totalKeysExamined” : 1001,
“totalDocsExamined” : 1000,
…
“direction” : “backward”,
“indexBounds” : {
“oid” : [
“[MaxKey, MinKey]”
],
“lastModifiedTime” : [
“(new Date(1554803097106), new Date(1554806697106))”
]
},
“keysExamined” : 1001,
“seeks” : 2,
可以看到,执行的效率更高了,几乎不需要什么 seeks 操作!
经过一番确认后,我们获知了在所有数据的分布中,工单号越大的记录其更新时间值也越大,基本上我们想查询的目标数据都集中在尾端。
于是就会出现一开始提到的,第一次查询非常慢甚至超时,而后面的查询就快了。
上面提到的两个查询执行路线如图所示:
加入$gt 条件,从中间开始检索
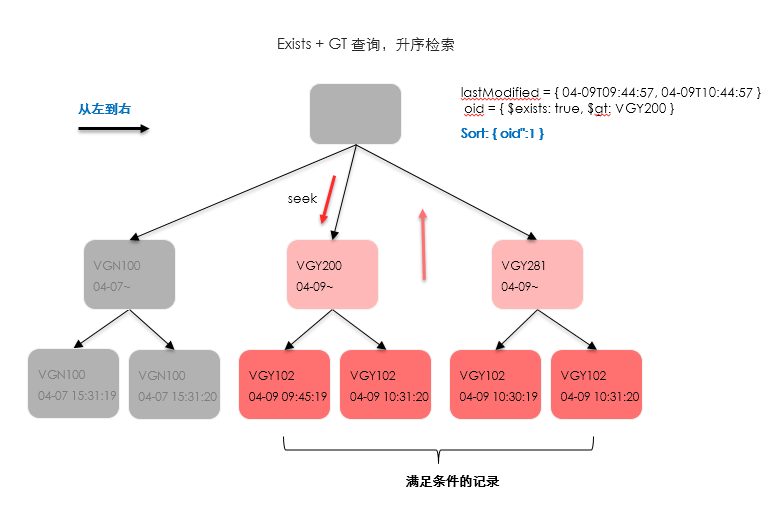
反序,从后面开始检索
优化思路
通过分析,我们知道了问题的症结在于索引的扫描范围过大,那么如何优化,以避免扫描大量记录呢?
从现有的索引及条件来看,由于同时存在gt、exists以及叶子节点的时间范围限定,不可避免的会产生seeks操作,
而且查询的性能是不稳定的,跟数据分布、具体查询条件都有很大的关系。
于是一开始所提到的仅仅是增加 socketTimeout 的阈值可能只是治标不治本,一旦数据的索引值分布变化或者数据量持续增大,可能会发生更严重的事情。
回到一开始的需求场景,定时器要求读取每天更新的工单(按工单号排序),再进行分批处理。
那么,按照化零为整的思路,新增一个lastModifiedDay字段,这个存储的就是lastModifiedTime对应的日期值(低位取整),这样在同一天内更新的工单记录都有同样的值。
建立组合索引 {lastModifiedDay:1, oid:1},相应的查询条件改为:
{
“lastModifiedDay”: new Date(“2019-04-09 00:00:00.000”),
“oid”: {$gt: “VXZ190”}
}
— limit 1000
执行结果如下:
“nReturned” : 1000,
“executionTimeMillis” : 6,
“totalKeysExamined” : 1000,
“totalDocsExamined” : 1000,…
“indexBounds” : {
“lastModifiedDay” : [
“(new Date(1554803000000), new Date(1554803000000))”
],
“oid” : [
“(\”VXZ190\”, {})”
]
},
“keysExamined” : 1000,
“seeks” : 1,
这样优化之后,每次查询最多只扫描1000条记录,查询速度是非常快的!
小结
本质上,这就是一种空间换时间的方法,即通过存储一个额外的索引字段来加速查询,通过增加少量的存储开销提升了整体的效能。
在对于许多问题进行优化时,经常是需要从应用场景触发,适当的转换思路。
比如在本文的问题中,是不是一定要增加字段呢?如果业务上可以接受不按工单号排序进行读取,那么仅使用更新时间字段进行分页拉取也是可以达到效果的,具体还是要由业务场景来定。
总结
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
