
SQL去重的3种实用方法总结
SQL去重的三种方法汇总
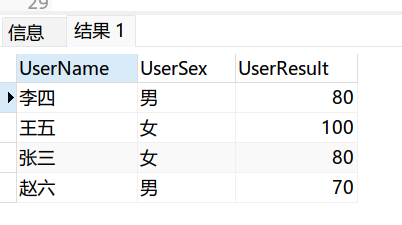
这里的去重是指:查询的时候, 不显示重复,并不是删除表中的重复项
1.distinct去重
注意的点:distinct
只能一列去重,当distinct后跟大于1个参数时,他们之间的关系是&&(逻辑与)关系,只有全部条件相同才会去重
弊端:当查询的字段比较多时,distinct会作用多个字段,导致去重条件增多
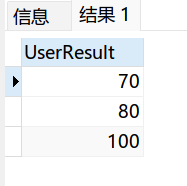
2.group by去重
去重原理:将重复的行进行分组,相同的数据只显示第一行
弊端:使用group by后,所有查询字段都需要使用聚合函数,比较繁琐
group by UserResult
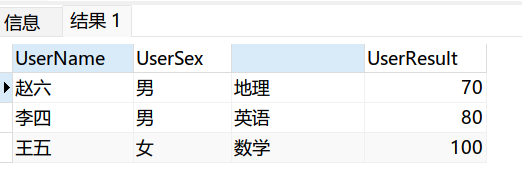
3.row_number() over (parttion by 分组列 order by 排序列)
弊端:小孟还不知道
去重原理:现根据重复列进行分组,分组后再进行排序,不同的组序号为1,相同的组序号为2,排除为2的就达到了去重效果
(
–查询出重复行
select *,row_number() over (partition by UserResult order by UserResult desc)num from Table1
)A
where A.num=1
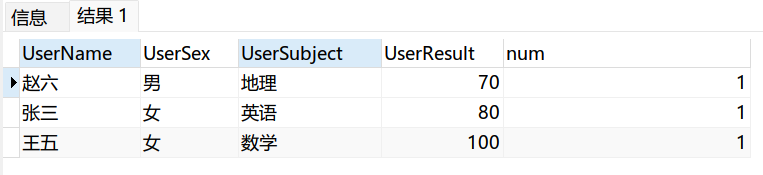
这里安利第三个,row_number(),稳一些!
补充:SQL根据某列或几列分组去重——row_number() over(partition by)的用法
有时利用SQL进行数据处理会发现,要根据某列或某几列选取信息,由于其他列不同而出现了多次,如运行程序1的结果图1:
程序1:
select a.*
from AShareEarningEst a
where a.S_INFO_WINDCODE in (‘000650.SZ’)
and a.REPORTING_PERIOD = 20181231
order by a.RESEARCH_INST_NAME,a.EST_DT
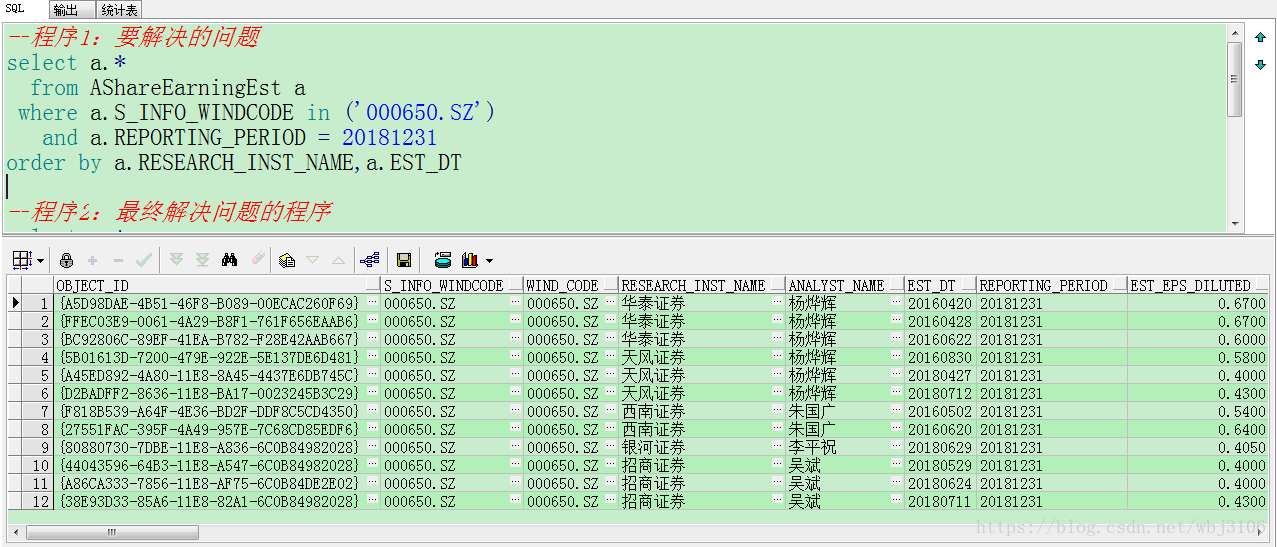
我们看到,在AShareEarningEst(中国A股盈利预测明细)表中,共有12人次的证券公司研究员,对000650.SZ(仁和药业)公司的20181231报告期进行预测。例:华泰证券的杨烨辉在20160420、20160428和20160622分别对000650.SZ(仁和药业)发布研究报告进行了预测。现在,我们只需要同一家证券公司的同一个研究员(此处假定同一家证券公司的研究员姓名相同时,即为同一个研究员)做出的最新预测数据,即根据证券公司名称、研究员姓名,同时根据估计日期进行筛选。
此时,可根据row_number() over(partition by)进行处理,运行程序2结果如图2:
程序2:
select b.*
from (select row_number() over(partition by a.RESEARCH_INST_NAME,
a.ANALYST_NAME order by est_dt desc) as rn,
–根据RESEARCH_INST_NAME(证券公司名称)和ANALYST_NAME(研究员名字)进行分类,
–同时根据est_dt(估计日期)倒序排序,即最新日期排在同一分类的上方,此时构建出rn为
a.*
from wdzx.AShareEarningEst a
where a.S_INFO_WINDCODE in (‘000650.SZ’) –, ‘000951.SZ’, ‘600006.SH’, ‘600166.SH’)
and a.REPORTING_PERIOD = 20181231) b –将分类后的程序构成表b。可以先运行b的程序观察结果
where b.rn = 1–运用表b的结果进行子查询,rn=1即为所需结果
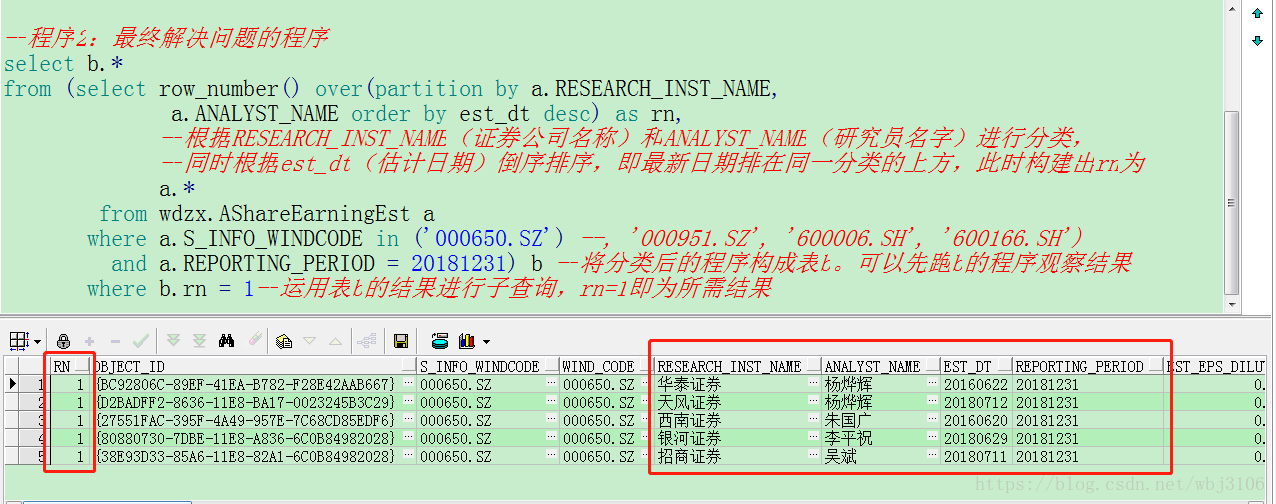
此时,即主要利用了row_number() over(partition by)函数筛选出了去重后的结果。
总结
到此这篇关于SQL去重的3种实用方法的文章就介绍到这了,更多相关SQL去重内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
