
教你如何给MongoDB数据库添加分片副本集
背景是这样的:线上一个MongoDB集群保存了很多历史数据,这些历史数据是按照时间字段进行分片的,最近到了2021年,有些分片的截止时间要到了,为了能容纳更多的数据,需要在当前分片的基础上增加相应的分片。
线上环境中,每个分片本身也是一个3副本的副本集,所以添加的时候有些特定的流程需要注意,我再测试环境中简单测了一下这个过程,记录下来。
整个过程大概的流程是:
1、新建分片副本集
2、使用addShard命令将分片副本集添加到集群中
3、使用addShardTag命令为分片打标签
4、使用addTagRange命令为打好标签的分片设置片键的数值区间,注意,各个分片的数值区间不能有重复。
目前测试环境的架构是:
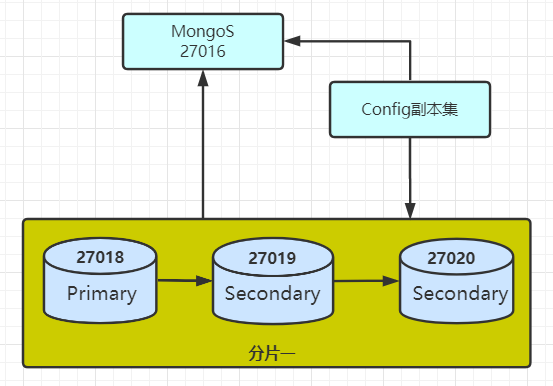
01 新建副本集
由于我们即将加入集群的分片是一个副本集,因此,需要提前将这个副本集创建好,创建的过程相对比较容易,按照之前的步骤来进行搭建,这里给出链接:
02 副本集添加到已有的集群中(addShard)
这一步也比较简单,可以直接在mongos上的admin数据库使用命令addShard即可:
db.runCommand({addShard:"sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026"})
当然,你也可以直接使用db.adminCommand命令来代替db.runCommand命令,这两个命令的区别是adminCommand命令默认是在admin数据库下面执行的,而runCommand默认的是当前数据库。
上面的命令,将本地的:
27024、27025、27026端口加入到集群中。到这里架构会变成:
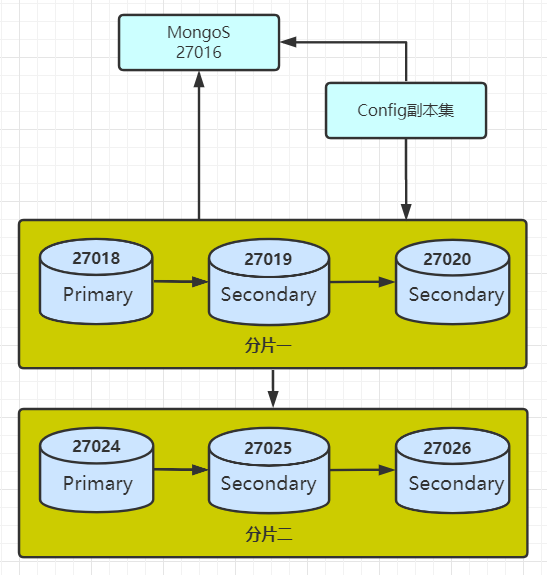
03 添加分片时间标签(addShardTag)
分片加入到集群之后,还需要对分片添加Tag,添加Tag的目的,是让我们知道,当前分片上保留的业务数据是哪一个时间段的。在测试环境中,我使用1_1000和1000_2000这两个tag来测试,命令如下:
sh.addShardTag("sharding_yeyz", "1_1000")
sh.addShardTag("sharding_yeyz1", "1000_2000")
对上面的命令简单进行解释,其中:
sharding_yeyz和sharding_yeyz1是分片副本集的名称;
1_1000和1000_2000是tag的名称。
添加完毕之后,我们可以通过系统的config库下面的tag表看到tag的情况,如下:
mongos> db.shards.find()
{ "_id" : "sharding_yeyz", "host" : "sharding_yeyz/127.0.0.1:27018,127.0.0.1:27019,127.0.0.1:27020", "state" : 1, "tags" : [ "1_1000" ] }
{ "_id" : "sharding_yeyz1", "host" : "sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026", "state" : 1, "tags" : [ "1000_2000" ] }
04 给打好的标签添加具体的数值范围(addTagRange)
设定好标签之后,需要设置每个标签所代表的分片上具体的数值范围,这就要用到addTagRange函数,使用方法如下:
sh.addTagRange( "new.test",
{ number: 1},
{ number: 1000},
"1_1000"
)
sh.addTagRange( "new.test",
{ number: 1000},
{ number: 2000},
"1000_2000"
)
注意,这里数值范围是指分片的那个集合的片键的数值范围。
分片永远是针对集合说的。
上面的命令是说,我们对数据库new下面的test集合做了分片,它的片键值是number这个字段:
当number属于[1,1000)的时候,该文档存放在tag是”1_1000″的这个分片上,也就是sharding_yeyz;
当number属于[1000,2000)的时候,该文档存放在tag是”1000_2000″的这个分片上,也就是sharding_yeyz1;
注意,区间为左闭右开。
05 查看结果
添加分片并设置分片的数值范围之后,我们可以使用:
db.printShardingStatus()命令或者sh.status()命令来查看当前集群中的分片情况:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5fafaf4f5785d9965548f687")
}
shards:
{ "_id" : "sharding_yeyz", "host" : "sharding_yeyz/127.0.0.1:27018,127.0.0.1:27019,127.0.0.1:27020", "state" : 1, "tags" : [ "1_1000" ] }
{ "_id" : "sharding_yeyz1", "host" : "sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026", "state" : 1, "tags" : [ "1000_", "1000_2000" ] }
active mongoses:
"4.0.6" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
sharding_yeyz 1
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : { "$maxKey" : 1 } } on : sharding_yeyz Timestamp(1, 0)
{ "_id" : "new", "primary" : "sharding_yeyz", "partitioned" : true, "version" : { "uuid" : UUID("68c70c64-f732-4478-8851-06dad4b94d6b"), "lastMod" : 1 } }
new.test
shard key: { "number" : 1 }
unique: false
balancing: true
chunks:
sharding_yeyz 3
sharding_yeyz1 1
{ "number" : { "$minKey" : 1 } } -->> { "number" : 1 } on : sharding_yeyz Timestamp(2, 1)
{ "number" : 1 } -->> { "number" : 1000 } on : sharding_yeyz Timestamp(1, 2)
{ "number" : 1000 } -->> { "number" : 2000 } on : sharding_yeyz1 Timestamp(2, 0)
{ "number" : 2000 } -->> { "number" : { "$maxKey" : 1 } } on : sharding_yeyz Timestamp(1, 5)
tag: 1_1000 { "number" : 1 } -->> { "number" : 1000 }
tag: 1000_2000 { "number" : 1000 } -->> { "number" : 2000 }
到了这里,我们开始验证最终的结果,先通过下面的命令生成一组测试数据,如下:
for (var i=1 ;i<=2000 ; i++){ db.test.insert({"number":i})}
去查看每个分片上的内容,可以发现:
sharding_yeyz
sharding_yeyz:PRIMARY> db.test.find().sort({"number":-1})
{ "_id" : ObjectId("5ffc051dd4c416daac620af5"), "number" : 2000 }
{ "_id" : ObjectId("5ffc0511d4c416daac620325"), "number" : 2000 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070c"), "number" : 999 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3c"), "number" : 999 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070b"), "number" : 998 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3b"), "number" : 998 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070a"), "number" : 997 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3a"), "number" : 997 }
{ "_id" : ObjectId("5ffc051bd4c416daac620709"), "number" : 996 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff39"), "number" : 996 }
{ "_id" : ObjectId("5ffc051bd4c416daac620708"), "number" : 995 }
这里需要注意,为什么2000这个值还是出现在分片一上呢?
这个原因是在设置分片的数值范围的时候,我们设置的区间是左闭右开的。而我们设置的分片范围分别是[1,1000)和[1000,2000),因此2000这个数字就被随机分配到这两个分片中,实际的情况是,它被分配到了分片一中。
sharding_yeyz1
sharding_yeyz1:PRIMARY> db.test.find().sort({"number":-1})
{ "_id" : ObjectId("5ffc051dd4c416daac620af4"), "number" : 1999 }
{ "_id" : ObjectId("5ffc0511d4c416daac620324"), "number" : 1999 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af3"), "number" : 1998 }
{ "_id" : ObjectId("5ffc0511d4c416daac620323"), "number" : 1998 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af2"), "number" : 1997 }
{ "_id" : ObjectId("5ffc0511d4c416daac620322"), "number" : 1997 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af1"), "number" : 1996 }
{ "_id" : ObjectId("5ffc0511d4c416daac620321"), "number" : 1996 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af0"), "number" : 1995 }
{ "_id" : ObjectId("5ffc0511d4c416daac620320"), "number" : 1995 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aef"), "number" : 1994 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031f"), "number" : 1994 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aee"), "number" : 1993 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031e"), "number" : 1993 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aed"), "number" : 1992 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031d"), "number" : 1992 }
这个结果看着就比较正常了。
今天的内容就到这里吧。
背景是这样的:线上一个MongoDB集群保存了很多历史数据,这些历史数据是按照时间字段进行分片的,最近到了2021年,有些分片的截止时间要到了,为了能容纳更多的数据,需要在当前分片的基础上增加相应的分片。
线上环境中,每个分片本身也是一个3副本的副本集,所以添加的时候有些特定的流程需要注意,我再测试环境中简单测了一下这个过程,记录下来。
整个过程大概的流程是:
1、新建分片副本集
2、使用addShard命令将分片副本集添加到集群中
3、使用addShardTag命令为分片打标签
4、使用addTagRange命令为打好标签的分片设置片键的数值区间,注意,各个分片的数值区间不能有重复。
目前测试环境的架构是:
01 新建副本集
由于我们即将加入集群的分片是一个副本集,因此,需要提前将这个副本集创建好,创建的过程相对比较容易,按照之前的步骤来进行搭建,这里给出链接:
02 副本集添加到已有的集群中(addShard)
这一步也比较简单,可以直接在mongos上的admin数据库使用命令addShard即可:
db.runCommand({addShard:"sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026"})
当然,你也可以直接使用db.adminCommand命令来代替db.runCommand命令,这两个命令的区别是adminCommand命令默认是在admin数据库下面执行的,而runCommand默认的是当前数据库。
上面的命令,将本地的:
27024、27025、27026端口加入到集群中。到这里架构会变成:
03 添加分片时间标签(addShardTag)
分片加入到集群之后,还需要对分片添加Tag,添加Tag的目的,是让我们知道,当前分片上保留的业务数据是哪一个时间段的。在测试环境中,我使用1_1000和1000_2000这两个tag来测试,命令如下:
sh.addShardTag("sharding_yeyz", "1_1000")
sh.addShardTag("sharding_yeyz1", "1000_2000")
对上面的命令简单进行解释,其中:
sharding_yeyz和sharding_yeyz1是分片副本集的名称;
1_1000和1000_2000是tag的名称。
添加完毕之后,我们可以通过系统的config库下面的tag表看到tag的情况,如下:
mongos> db.shards.find()
{ "_id" : "sharding_yeyz", "host" : "sharding_yeyz/127.0.0.1:27018,127.0.0.1:27019,127.0.0.1:27020", "state" : 1, "tags" : [ "1_1000" ] }
{ "_id" : "sharding_yeyz1", "host" : "sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026", "state" : 1, "tags" : [ "1000_2000" ] }
04 给打好的标签添加具体的数值范围(addTagRange)
设定好标签之后,需要设置每个标签所代表的分片上具体的数值范围,这就要用到addTagRange函数,使用方法如下:
sh.addTagRange( "new.test",
{ number: 1},
{ number: 1000},
"1_1000"
)
sh.addTagRange( "new.test",
{ number: 1000},
{ number: 2000},
"1000_2000"
)
注意,这里数值范围是指分片的那个集合的片键的数值范围。
分片永远是针对集合说的。
上面的命令是说,我们对数据库new下面的test集合做了分片,它的片键值是number这个字段:
当number属于[1,1000)的时候,该文档存放在tag是”1_1000″的这个分片上,也就是sharding_yeyz;
当number属于[1000,2000)的时候,该文档存放在tag是”1000_2000″的这个分片上,也就是sharding_yeyz1;
注意,区间为左闭右开。
05 查看结果
添加分片并设置分片的数值范围之后,我们可以使用:
db.printShardingStatus()命令或者sh.status()命令来查看当前集群中的分片情况:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5fafaf4f5785d9965548f687")
}
shards:
{ "_id" : "sharding_yeyz", "host" : "sharding_yeyz/127.0.0.1:27018,127.0.0.1:27019,127.0.0.1:27020", "state" : 1, "tags" : [ "1_1000" ] }
{ "_id" : "sharding_yeyz1", "host" : "sharding_yeyz1/127.0.0.1:27024,127.0.0.1:27025,127.0.0.1:27026", "state" : 1, "tags" : [ "1000_", "1000_2000" ] }
active mongoses:
"4.0.6" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
sharding_yeyz 1
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : { "$maxKey" : 1 } } on : sharding_yeyz Timestamp(1, 0)
{ "_id" : "new", "primary" : "sharding_yeyz", "partitioned" : true, "version" : { "uuid" : UUID("68c70c64-f732-4478-8851-06dad4b94d6b"), "lastMod" : 1 } }
new.test
shard key: { "number" : 1 }
unique: false
balancing: true
chunks:
sharding_yeyz 3
sharding_yeyz1 1
{ "number" : { "$minKey" : 1 } } -->> { "number" : 1 } on : sharding_yeyz Timestamp(2, 1)
{ "number" : 1 } -->> { "number" : 1000 } on : sharding_yeyz Timestamp(1, 2)
{ "number" : 1000 } -->> { "number" : 2000 } on : sharding_yeyz1 Timestamp(2, 0)
{ "number" : 2000 } -->> { "number" : { "$maxKey" : 1 } } on : sharding_yeyz Timestamp(1, 5)
tag: 1_1000 { "number" : 1 } -->> { "number" : 1000 }
tag: 1000_2000 { "number" : 1000 } -->> { "number" : 2000 }
到了这里,我们开始验证最终的结果,先通过下面的命令生成一组测试数据,如下:
for (var i=1 ;i<=2000 ; i++){ db.test.insert({"number":i})}
去查看每个分片上的内容,可以发现:
sharding_yeyz
sharding_yeyz:PRIMARY> db.test.find().sort({"number":-1})
{ "_id" : ObjectId("5ffc051dd4c416daac620af5"), "number" : 2000 }
{ "_id" : ObjectId("5ffc0511d4c416daac620325"), "number" : 2000 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070c"), "number" : 999 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3c"), "number" : 999 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070b"), "number" : 998 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3b"), "number" : 998 }
{ "_id" : ObjectId("5ffc051bd4c416daac62070a"), "number" : 997 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff3a"), "number" : 997 }
{ "_id" : ObjectId("5ffc051bd4c416daac620709"), "number" : 996 }
{ "_id" : ObjectId("5ffc050fd4c416daac61ff39"), "number" : 996 }
{ "_id" : ObjectId("5ffc051bd4c416daac620708"), "number" : 995 }
这里需要注意,为什么2000这个值还是出现在分片一上呢?
这个原因是在设置分片的数值范围的时候,我们设置的区间是左闭右开的。而我们设置的分片范围分别是[1,1000)和[1000,2000),因此2000这个数字就被随机分配到这两个分片中,实际的情况是,它被分配到了分片一中。
sharding_yeyz1
sharding_yeyz1:PRIMARY> db.test.find().sort({"number":-1})
{ "_id" : ObjectId("5ffc051dd4c416daac620af4"), "number" : 1999 }
{ "_id" : ObjectId("5ffc0511d4c416daac620324"), "number" : 1999 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af3"), "number" : 1998 }
{ "_id" : ObjectId("5ffc0511d4c416daac620323"), "number" : 1998 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af2"), "number" : 1997 }
{ "_id" : ObjectId("5ffc0511d4c416daac620322"), "number" : 1997 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af1"), "number" : 1996 }
{ "_id" : ObjectId("5ffc0511d4c416daac620321"), "number" : 1996 }
{ "_id" : ObjectId("5ffc051dd4c416daac620af0"), "number" : 1995 }
{ "_id" : ObjectId("5ffc0511d4c416daac620320"), "number" : 1995 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aef"), "number" : 1994 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031f"), "number" : 1994 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aee"), "number" : 1993 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031e"), "number" : 1993 }
{ "_id" : ObjectId("5ffc051dd4c416daac620aed"), "number" : 1992 }
{ "_id" : ObjectId("5ffc0511d4c416daac62031d"), "number" : 1992 }
这个结果看着就比较正常了。
今天的内容就到这里吧。
以上就是如何为MongoDB添加分片副本集的详细内容,更多关于为MongoDB添加分片副本集的资料请关注其它相关文章!
