
MySQL中B树索引和B+树索引的区别详解
如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,也就是一页,而二叉树的每个节点只存储一条数据,并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据的数据结构,也就是多路搜索树。
1. 多路搜索树
1、完全二叉树高度:O(log2N),其中2为对数,树每层的节点数;
2、完全M路搜索树的高度:O(logmN),其中M为对数,树每层的节点数;
3、M路搜索树主要用于解决数据量大无法全部加载到内存的数据存储。通过增加每层节点的个数和在每个节点存放更多的数据来在一层中存放更多的数据,从而降低树的高度,在数据查找时减少磁盘访问次数。
4、所以每层的节点数和每个节点包含的关键字越多,则树的高度越矮。但是在每个节点确定数据就越慢,但是B树关注的是磁盘性能瓶颈,所以在单个节点搜索数据的开销可以忽略。
2. B树-多路平衡搜索树
B树是一种M路搜索树,B树主要用于解决M路搜索树的不平衡导致树的高度变高,跟二叉树退化为链表导致性能问题一样。B树通过对每层的节点进行控制、调整,如节点分离,节点合并,一层满时向上分裂父节点来增加新的层等操作来来保证该M路搜索树的平衡。
M为B树的阶数或者说是路数,在B树中,每个节点都是一个磁盘块(页)。每个非叶子节点存放了关键字和指向儿子树的指针,具体数量为:M阶的B树,每个非叶子节点存放了M-1个关键字和M个指向子树的指针。如图为5阶B树结构的示意图:
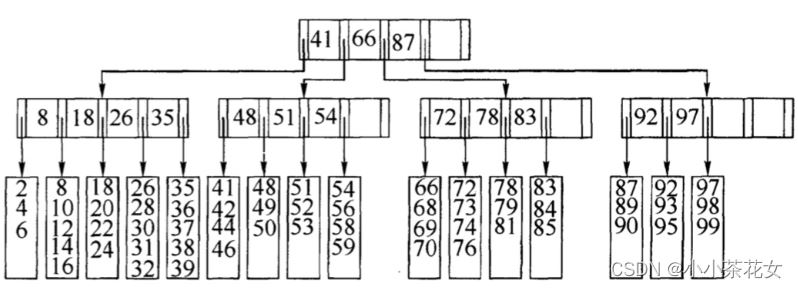
3. B树索引
首先创建一张user表:
id int,
name varchar,
primary key(id)
) ROW_FORMAT=COMPACT;
假如我们使用B树对表中的用户记录建立索引:
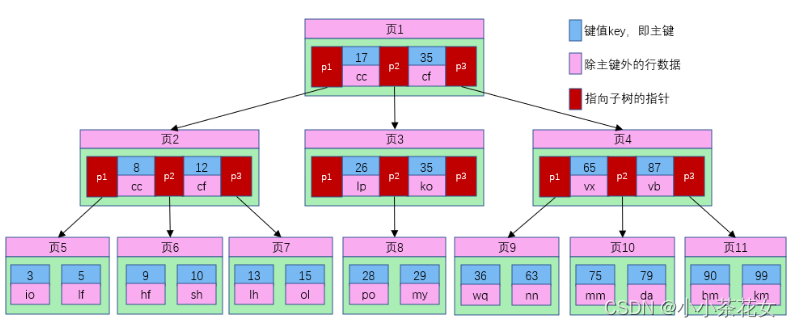
B树的每个节点占用一个磁盘块,磁盘块也就是页,从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的主键key和数据data,并且每个节点拥有了更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会降低。假如我们要查找id=28的用户信息,那么查找流程如下:
1、根据根节点找到页1,读入内存。【磁盘I/O操作第1次】
2、比较键值28在区间(17,35),找到页1的指针p2;
3、根据p2指针找到页3,读入内存。【磁盘I/O操作第2次】
4、比较键值28在区间(26,35),找到页3的指针p2。
5、根据p2指针找到页8,读入内存。【磁盘I/O操作第3次】
6、在页8中的键值列表中找到键值28,键值对应的用户信息为(28,po);
B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
4. B+树索引
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,B+树的性质:
1、非叶子节点的子树指针与关键字个数相同;
2、为所有叶子节点增加一个链指针;
3、所有关键字都在叶子节点出现, 且链表中的关键字恰好是有序的;
4、非叶子节点相当于是叶子节点的索引,叶子节点相当于是存储(关键字)数据的数据层;
InnoDB存储引擎就是用B+Tree实现其索引结构。
从上一节中的B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
1、非叶子节点只存储键值信息和指向子节点页号的指针;
2、所有叶子节点之间都有一个链指针;
3、数据记录都存放在叶子节点中;
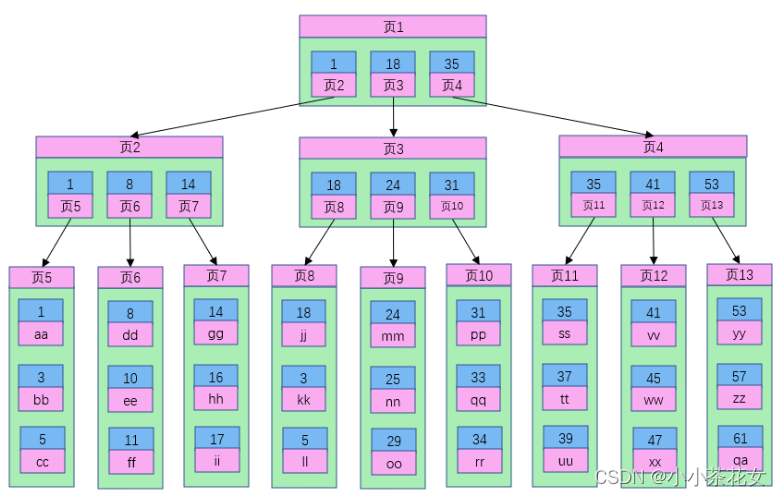
根据上图我们来看下 B+ 树和 B 树有什么不同:
(1) B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据。
页的大小是固定的,InnoDB 中页的默认大小是 16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快。
另外,如果我们的 B+ 树一个节点可以存储 1000 个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。一般根节点是常驻内存的(第一次检索根节点不用读取磁盘),所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
(2) B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的,通过这种方式可以找到表中的所有数据。B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!
